
Time series classification – an overview
Time series classification (Fig. 1) is a relative late bloomer in the field of machine learning. However, in recent years there has been a real surge of data, algorithms and open source code that can be used to tackle problems in new and better ways.
This blog post aims to give a basic overview of the field. My aim is that it should be possible to follow for the interested reader even without a background in machine learning. Hopefully this will give you readers an overview and further avenues for explorations.
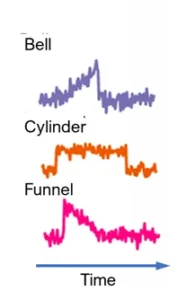
Fig. 1. Time series classification example. Samples from the widely used synthetic Cylinder-Bell-Funnel (CBF) benchmark dataset [1]. Each time series belongs to one of three classes: cylinders, bells and funnels. Adapted from [2] with permission from Patrick Schäfer.
Examples of time series and classification problems
A time series is just one (uni-dimensional) or several (multi-dimensional) temporally ordered sequences of numeric values. They are ubiquitous since anything numeric that you measure over time or in a sequence is a time series. For example:
- The temperature in Stockholm each day during 2020 (a uni-dimensional time series).
- Sales records
- Video (a multi-dimensional time series where each image corresponds to a time point. Note that here the data is also ordered in the pixel dimensions).
- Audio recordings.
- Internet-of-things and other sensor data.
- ECG/EEG and other medical signals.
- Transport data (e.g. when studying road congestion).
- The growth curve of a child (here the time points are not equally spaced, so this puts special demands on the algorithms).
Other types of data can also be viewed as/transformed into time series, such as written text, which is basically a time series but where the entities are not numeric. The beauty of this is that it lends the possibility to analyze time series using language models and to analyze language using time series models.
Time series classification problems are everywhere, so it is hard to know where to start, but the following are some random examples of making classifications from time series data:
- Classify of whom a voice recording is
- Classify an ECG as normal or give the type of abnormality.
- Surveillance: From a video, capture the path of an individual, then classify what he/she is doing.
- Internet-of-things: classify whether a kitchen device is malfunctioning.
- Speech recognition
- Classification of brain imaging or genetic expression data
You can imagine yourself that the applications of good algorithms are essentially without limit.
What is time series classification with machine learning?
In essence, time series classification is a type of supervised machine learning problem. Supervised problems have the following procedure: You get a set of time series, each with a class label. You typically divide the time series into three groups, the training data, the validation data and the test data. You train a number of algorithms/models on time series in the training data, observe which algorithm performs the best on the validation data and choose that one. Finally, you use the test data to determine the performance of the chosen algorithm.
The difference to many classification problems in machine learning is that the data is ordered along the time dimension, and as such a good algorithm would need to exploit this property of the data.
One should not confuse time series classification with forecasting. The purpose is different and hence the algorithms are, too. Forecasting aims to predict the next future values, and as such often relies more heavily on the end of a time series. It doesn’t need to compare different time series with each other. Rather it needs to find recurring patterns in data that are predictive of the (immediate) future. Classification on the other hand needs to find patterns in the data that are different between different classes in order to determine the class of the time series at hand.
So what are some of the algorithms used for time series classification?
Dynamic time warping, a benchmark algorithm
For at least a decade, a technique called dynamic time warping (DTW) combined with 1-nearest neighbor (1-NN) has been a benchmark for other time series classification algorithms to beat [3]. 1-nearest neighbor (Fig. 2) is a simple technique where you have a training set of time series [4]. You then classify a new incoming time series by finding the time series in the training data that is most similar, and assign the new time series to the same class as that one. You can also have k-nearest neighbors, where you find the k most similar time series and choose the most common class amongst those.
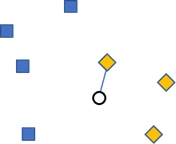
Fig. 2. 1-nearest neighbor. Based on a dataset of two classes (blue and yellow), a new datapoint (circle) is to be classified. By finding the nearest datapoint, the new datapoint can be classified as belonging to the yellow class.
DTW [5] is used to calculate the distance between two time series (Fig. 3); without a distance 1-NN cannot determine which time series is nearest. The most naive way would be to just take the distance between each point in the time series. However, it is not necessarily clear which points should be compared to which in the two time series. For instance, if two identical time series are just shifted slightly, then this would result in a big distance. DTW solves this by pairing up the different time points by drawing lines between them in such a way that each time point in a series must be connected to a time point in the other series, and two lines must never cross (Fig. 3). The distance is the sum of the difference between the paired time points. DTW chooses the grey lines in a way that minimizes this distance.

Fig 3. DTW. Points in two time series are connected in a way to minimize the distance between two time series (the combined length of all the grey lines). As can be seen from the gray lines being tilted, the latter half of the blue time series is shifted to the right of the latter part of the red time series. DTW is able to connect the corresponding points of the two series to calculate the minimum distance. Adapted from [6] with permission from Brian Iwana.
The benefits of a machine learning model
DTW+1-NN doesn’t build a machine learning model of what time series for a different class should look like. What I mean is, there is no model holding an internal representation of the world, no knowledge stored in any model weights. Instead it reaches its conclusions simply following a step-by-step procedure where it compares new time series to series in the training data. The benefit is that no model training is needed. But there are several drawbacks.
Firstly, classification takes a lot of time. For each new time series one must calculate the distance to all the time series in the training data. DTW is in itself an optimization problem, which means that the distance calculation is fairly slow, and for a big data set consisting of millions of data time series it must be repeated over and over again. Hence, it doesn’t scale beyond fairly small problems.
Secondly, a machine learning model is a way to capture our knowledge of data in a parsimonious way. For a real-life analogy, having a model is akin to having an expert at hand. The expert can just look at your new time series and say which class it belongs to. Training a human expert takes a long time, but once that is done, classification is fast. On the other hand, DTW+1-NN is like working with a non-expert given a recipe for how to go through the data and determine the class.
Having once captured your knowledge into a machine learning model means that you can employ this knowledge in many situations that are similar but not identical, a technique called transfer learning. For example, consider a model that has looked at many bird songs in order to separate between nightingales and canaries. In order to do so, it has had to learn many features of bird songs in general. If we now wanted to separate between a robin and a sparrow, we could use our previous model and just finetune it to hear the difference between these two species. This would be much easier than training a new model, because the old model has a good ear for bird songs in general already, so much less training data would be needed.
You might think that transfer learning would only be useful in obviously similar cases such as the above. Think again. Image classification has been a resounding success due to the availability of huge benchmark datasets of millions of images coupled with competitions that have driven the development of algorithms to beat previous records on those datasets [7, 8, 9]. Researchers have for some time now transformed one-dimensional time series into two-dimensional images using techniques such as gramian angular fields, and been able to classify these time series images successfully [10]. Think about how wild this is! The network has been studying photos of cars and airplanes and somehow learnt something useful for classifying bird songs. When I first heard that learning can transfer that far I was just blown away. The reason why this works is that there is some similarity on some level between the time series images and real images on which the network was first trained.
The above example is interesting from another aspect as well. We have a 2-D image model which is sub-optimal compared to a tailor-made 1-D time series model. However, since the image model has had much more training data, it performs better. It is the model-data combo that determines the performance, not the model in isolation.
Recent developments / Other approaches
Data availability
For time series, there exists a repository of datasets called UCR/UEA [1, 11] (from Univerisity of California, Riverside and University of East Anglia). It displays a wide variety of time series and all algorithms are benchmarked against it. In this way it is immensely useful in determining the relative performance of various algorithms. Compared to the corresponding benchmark repositories for images, text, etc, it suffers from being much smaller, having just on the order of 100 datasets, and with the biggest containing less than 10000 samples. For text, for example, you can download the whole of wikipedia very quickly. This comparative lack of data is hampering the development of the field. However, the repository is growing and being added upon every few years (most recently in 2018), which benefits research.
Perhaps due to relative lack of data, it has been difficult for new algorithms to beat DTW+1-NN, since more complex models would need more data to train all the parameters on. Below I describe some of the approaches that have performed better than DTW+1-NN.
Shapelets
One technique is to use shapelets [12]. A shapelet is a short time series that has been chosen because it is very indicative of a class (Fig. 4). For example, it could be a particular electrical pattern that is only emitted by microwave ovens and as such can be used when classifying home appliances. Shapelets are different from DTW because they focus on only parts of the time series. When you pass a time series through a shapelet algorithm the output is the minimum distance between the shapelet and all subsequences of the time series (this is called a shapelet transform). This data can then be used to train a classification algorithm, e.g. 1-NN or a machine learning model. In [13] an ensemble (see explanation below) of classifiers based on shapelet-transformed data was second best on the UCR/UEA dataset of all tested algorithms.
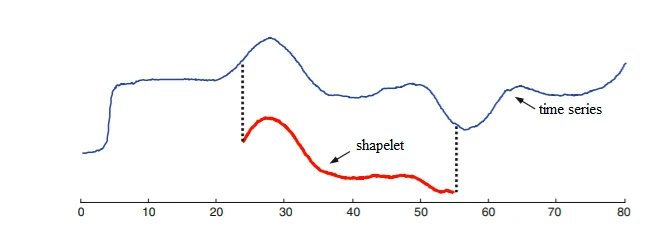
Fig. 4. Shapelets are small pieces of time series associated with a class. The distance between the time series (blue) and the shapelet (red) is the shortest distance between the shapelet and any part of the time series (here indicated by the dots). Taken from [14] with permission from Alexandra Amidon.
The main difficulty when using shapelets is that it can be hard to know which shapelets to use. One possibility is to manually craft a set of shapelets, but this can be quite difficult and time consuming. A better solution, if possible, is to automatically select shapelets. The way to do this best is an active field of research to a problem that is quite tricky due to the enormous amount of possible shapelets (see [15], section VI, and [13] for a good overview).
Another problem is really bad time complexity (how the execution time scales with the data): O(n2l4), where n is the number of training samples and l is the shapelet length [13]. This means that doubling the training data leads to a 4-fold slowdown and doubling the shapelet length leads to a 16-fold slowdown.
Model ensembles
Another approach has been to create model ensembles. “Collective of Transformation-Based Ensembles” (COTE) [16] from 2015 and its development HIVE-COTE from 2016 [17] are ensembles (collections, see below) consisting of many different models. COTE managed to increase the accuracy with 8% on the UCR/UEA datasets vs DTW+1-NN [13], which was the best of all algorithms tested. HIVE-COTE then significantly outperformed COTE and is the best algorithm to date that is not a neural network.
An ensemble is a collection of models each with its own classification, from which you pick the most common one. This works well if models have good enough accuracy and the errors that each model makes is different. For example, having three uncorrelated models with 90% accuracy each, for a given time series there is a 0.1*0.9*0.9 = 0.081 chance of one model giving the wrong answer, a 0.1*0.1*0.9 = 0.009 chance of two models giving the wrong answer and a 0.1*0.1*0.1 = 0.001 chance of three models giving the wrong answer. Taking the majority vote, the ensemble would give the wrong answer only in the latter two cases, representing 0.009 + 0.001 = 0.01 = 1%. Thus we have increased the accuracy of the ensemble to 99% vs the 90% of the single model.
An important factor for an ensemble is the degree to which the algorithms are uncorrelated (produce errors in different places). If all algorithms are totally correlated, they will produce the same results and so the ensemble will have the same accuracy as the individual algorithms. The authors of COTE noted that several of the 35 employed algorithms were minor variations of the same team (e.g. 50% worked in on auto-correlation and spectrum features). HIVE-COTE tried to address this by creating a hierarchy whereby all the algorithms were first grouped by type (DTW-based, dictionary-based, etc). Each major group first produced a joint classification and that was then entered into the ensemble classification. In this way they were able to avoid that the ensemble was dominated by one group of correlated algorithms, with the result of improved performance.
The biggest problem with COTE and HIVE-COTE is that several of the models rely on the shapelet transform and hence suffer from very bad time complexity, meaning that they take ages to run on a big dataset [13]. For this reason, the community has looked for faster alternatives. Another ensemble, TS-CHIEF, although not having higher accuracy than HIVE-COTE, is one such choice [18].
With so many models it is also very difficult to understand why the models classify the way they do. Interpretability is tremendously important. For example, it is not enough for a physician to say that you belong to the class of people for which there are little chances of survival in case of contracting corona virus and therefore we will not give you treatment.
Dictionary-based approaches
A third popular collection of techniques is called dictionary-based [13]. Basically, a dictionary is a list of words where you look up a word to retrieve something, e.g. an explanation of the word or the number of occurrences of the word in a text. So for instance one could classify a text as belonging to a type of field (e.g. sports vs law) by comparing the occurrences of different words.
But how does this apply to time series classification? Well, there are several ways to construct dictionaries for time series. One could use the shapelet approach above [12, 15] to count the number of times in a time series where there is a match between the shapelet and the time series. In such a dictionary the shapelet takes the place of the word and what you retrieve is the number of matches of the shapelet for the time series. An algorithm called ROCKET [19] is currently among the top-performing time series algorithms and does something similar. It has a large number of random kernels (very similar to shapelets) and they calculate for each kernel the percent matches. A simple classifier (logistic or ridge regression) is trained on the dictionary.
Another is the Bag-of-Patterns (BOP) algorithm [20]. It actually underperforms against DTW+1-NN [13], but I include it here because it illustrates the approach well. Like the Bag-of-Words algorithm used for text data, this algorithm counts the number of times a word occurs, only this time the words are created from numbers using a technique called Symbolic Aggregate approXimation (SAX) [21]. A bit oversimplified, you first split the time series into a number of larger time segments and normalize. Next you define intervals of the signal (y) value and assign a letter to each (e.g. A: <-0.3, B: -0.3 to 0.3, C: >0.3). You finally cut each segment into small pieces, calculate the mean for each piece and translate it to one of the letters (A, B, C in this case). In this way each segment consists of a string of letters, e.g. ABBC. You can then summarize the number of occurrences of each string into a dictionary, which can be used for classification.
Other dictionary approaches have been more successful, in particular an algorithm called BOSS [2]. It works similarly to BOP, but instead of translating the normalized original signal into words it works by Fourier transforming the signal into frequency space, low-pass filtering it and translating it into words using two algorithms called SFA and MCB. This has the effect of reducing noise. Furthermore, it creates an ensemble of different models that vary by the amount of low-pass filtering and the word length. In a comparison between many different algorithms on datasets from UCR/UEA, the BOSS algorithm was among the best, and is much faster on big datasets than COTE (complexity: O(n2l2)) [13].
One of the main reasons why dictionary based approaches work well is that the translation into words make them robust to noise.
Interval-based classification
The most typical interval-based algorithm would be the time series forest [22], a type of random forest. A forest is a collection of decision trees. Each decision tree is a machine learning model that takes a data point and assigns a class based on the value of its variables, as shown in Fig. 5. By creating a number of trees, each which gets to see a different part of the data, you end up with an ensemble of different tree classifiers (i.e. the forest), each possibly producing a different classification (since it has been trained on slightly different data). You then follow the usual ensemble procedure and choose the most common prediction as your final prediction.
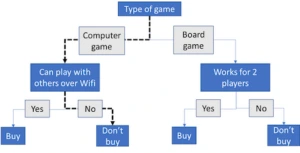
Fig. 5. Decision tree example. A decision tree takes a data point, in this case a game, which can be characterized along a number of different dimensions (here 3: a. type of game, b. multiplayer via Wifi, c. works for 2 players). By traversing the tree, we end up at a purchase decision (as illustrated by the dashed line, a computer game that does not allow for game play via Wifi will not be bought). In a random forest ensemble the aim is to produce trees with different structure whose errors are uncorrelated.
The special thing of a time series forest is that you divide your time series into n distinct intervals and for each interval you calculate the 3 values mean, standard deviation and slope [21]. Thus you end up with 3n variables that you input into the model. One of the tricks is to find how you split your time series into intervals. The performance of time series forests are not as good as BOSS or COTE [13].
Deep learning
Deep learning models are types of neural networks consisting of several, often many, layers of neurons (See [23] for a simple introduction). They typically contain many more parameters than other machine learning models. Often they consist of a “body” of layers to which data is fed. Whereas early layers represent basic shapes (e.g. a horizontal line in image models), the later layers encode semantically meaningful representations. Thus, the output layer of the body (the “neck”?) should contain what is meaningful and salient in the data. For example, in image classification the body can capture the presence of a car wheel and the neck all the information needed to discriminate between different makes, models and versions. On top of that is a “head” which is a classifier of some sort that makes a classification based on the output of the neck. By working on the neck rather than directly on the image, it is easier for the head to classify data into e.g. cars vs airplanes. In the last decade, deep learning models have become the obvious choice for classification of both images and language. For time series it has only recently gained in popularity somewhat, but still performance on the UCR/UEA datasets is as good as HIVE-COTE [3, 19, 24] despite being much faster.
Ways of training deep learning models
There are perhaps two different ways to train a deep learning model for time series classification (as is the case for many types of deep learning): unsupervised (generative) and supervised (discriminative) [23]. Supervised is what we talked about above. This is where you train the model to generate the correct classification. One problem with this approach is that the classes contain only little information (for a two-class problem only 1 bit of information), whereas the time series contains a lot more and the model has many parameters to be tuned. With generative learning one instead trains a model to output a whole time series. One approach is the auto-encoder, where one replaces the head with an inverted body. Since the neck contains a distillate of the information of the time series, by passing it through the inverted body one should be able to regenerate the original time series. Since the time series contains more information than the class, the network is trained to capture all the information in the neck that is needed to regenerate the time series well enough. Having performed basic training, one can then remove the inverted body and replace it with a head that you can then train on the classification task at hand. TimeNet is an example of this approach [25].
Model types
There are many different types of deep learning models. Since the field moves quickly in this area, I will not go into detail concerning the specific architectures. They are generally one-dimensional, and often are causal (meaning that a value only depends on historical values, not future ones). Previous models were often of a type called recurrent networks, but recently the most successful architectures have been so-called convolutional networks. Some of the architectures that perform at least as well as COTE are ResNet [3], Fully Convolutional Networks [3] (that can handle time series of different length), multi-scale convolutional neural networks [3] and InceptionTime [26].
Lack of data problem
Lack of data might be the main reason why training from scratch of deep learning models tailored specifically for time series data has not previously been able to beat the more traditional algorithms on the UCR/UEA datasets. This is suggested by the big discrepancy between time series and image dataset sizes [6] as well as the improvement of classification accuracy with deep learning model ResNet when synthetic data is added to the smallest datasets in UCR/UEA [27]. We end this section with some approaches to tackle the data problem.
ROCKET [19] is a model (not a typical neural network but with many similarities) that has taken the radical approach of randomly setting the weights of the model body without training. It chooses a large collection of different weights of various magnitudes in the hope that they will be able to capture a large variety of patterns in the data. This model has very similar performance to HIVE-COTE.
Another approach has been transfer learning. TimeNet [25] is created specifically to serve as a pretrained and publicly available time-series specific deep learning network for common use. There is also the transfer learning from image models mentioned above.
Finally, a third approach has been to increase the amount of data by producing artificial data. A good overview is given in two articles by Iwana and Uchida [6, 28]. This technique is called data augmentation and merits a blog post of itself, but one of the approaches has been to take two time series from the data belonging to the same class and mixing them. The secret of the sauce is how to do the mixing properly. As when calculating the distance between time series, one needs to find out which pairs of data points in two series are corresponding. So one approach has been to use DTW to pair up the time points of two different series and then take an average of the paired data points. Currently data augmentation is not an established practice in time series classification whereas it is in image classification [6, 28], but this is a field that will become much more important in the future. It will probably boost the performance of most algorithms, but especially more complex models such as deep learning models.
Last words
Above I have tried to give an outline to the enormous field of time series classification. For readers, whether you do or do not know machine learning, I hope that the above can guide you and set expectations should you start a time series classification project. One suggestion would be to find a dataset from UCR/UEA [1] that is similar to yours in order to get an idea of what could be achieved. If you know how to code and want to try out an algorithm, I suggest you download a dataset from UCR/UEA and try out a basic algorithm such as DTW+1-NN ([29] for a Python implementation) or one of the algorithms that perform well on a suitable UCR/UEA dataset. There are many algorithms out there, and many of the articles reviewed above come with source code from Papers with code [30]. Note however that the code is written by researchers and not professional developers, which means that the code might require some tweaking.
Working on a machine learning project is similar in many ways to working on a code development project. It is great to try things out on your own. Still, just like most code development work sooner or later needs developers, the same goes for machine learning projects.
References
- UEA & UCR Time Series Classification Repository. timeseriesclassification.com.
- Schäfer, P. (2015) The BOSS is concerned with time series classification in the presence of noise. Data Min Knowl Discov 29, 1505–1530.
- Wang Z. et al. (2017) Time Series Classification from Scratch with Deep Neural Networks: A Strong Baseline. IJCNN 2017: 1578-1585.
- Cover T.M., Hart P.E. (1967) Nearest neighbor pattern classification IEEE Trans Inf Theory 13(1)21–27.
- Müller M. (2007) Dynamic Time Warping In Information Retrieval for Music and Motion 69-84
- Iwana B. K., Uchida S. (2020) Time Series Data Augmentation for Neural Networks by Time Warping with a Discriminative Teacher. arXiv:2004.08780v1.
- Sultana F. et al (2018) Advancements in Image Classification using Convolutional Neural Network 4th Int Conf Res Comput Intell Commun Netw (ICRCICN), Kolkata, India, 122-129
- Krizhevsky A (2009) Learning Multiple Layers of Features from Tiny Images.
- Imagenet. www.image-net.org.
- Wang Z., Oates T. (2015) Imaging Time-Series to Improve Classification and Imputation. In: 24 Int Joint Conf Arti Intell.
- Dau H.A. et al (2019) The UCR Time Series Archive IEEE/CAA J Autom Sinica, (6) 6, 1293-1305
- Ye L., Keogh E. (2009) Time series shapelets: a new primitive for data mining. In KDD ’09: Proc 15th ACM SIGKDD Int Conf Knowl Discov Data Min.
- Bagnall, A. et al. (2016) The great time series classification bake off: a review and experimental evaluation of recent algorithmic advances. Extended Version. arXiv:1602.01711.
- Amidon A. (2020) A Brief Survey of Time Series Classification Algorithms Towardsdatascience.com.
- Gupta A. et al (2020) Approaches and Applications of Early Classification of Time Series: A Review arXiv:2005.02595v2.
- Bagnall A. et al. (2015) Time-Series Classification with COTE: The Collective of Transformation-Based Ensembles. In IEEE Trans Knowl Data Eng., 27, (9) 2522-2535.
- Lines J. et al. (2016) HIVE-COTE: The Hierarchical Vote Collective of Transformation-Based Ensembles for Time Series Classification. In IEEE 16th Int Conf Data Min (ICDM), 1041-1046.
- Shifaz A. (2020) TS-CHIEF: A Scalable and Accurate Forest Algorithm for Time Series Classification. Data Min Knowl Discov 34, 742-75.
- Dempster A., Petitjean F, Webb G.I. (2020) ROCKET: exceptionally fast and accurate time series classification using random convolutional kernels. Data Min Knowl Discov 34, 1454–1495.
- Lin J.et al (2007) Experiencing SAX: a novel symbolic representation of time series. Data Min and Knowl Discov, 15(2):107–144
- Lin J., R. Khade, and Y. Li. (2012) Rotation-invariant similarity in time series using bag-of-patterns representation. J Intell Inf Sys, 39(2):287–315
- Deng et al. (2013) A time series forest for classification and feature extraction. Inf Sci 239, 142-153.
- Kaggle Intro to Deep Learning.
- Fawaz H.I. et al (2019) Deep learning for time series classification: a review Data Min Knowl Disc 33, 917–963
- Malhotra P. et al. (2017) TimeNet: Pre-trained deep recurrent neural network for time series classification In: ESANN 2017 proc, Eur Symp Artif Neural Netw Comput Intell Mach Learn Bruges (Belgium).
- Fawaz H.I. (2020) InceptionTime: Finding AlexNet for time series classification Data Min Knowl Discov 34 1936–62
- Fawaz H.I. et al (2018) Data augmentation using synthetic data for time series classification with deep residual networks arXiv:1808.02455.
- Iwana B. K., Uchida S. (2020) An Empirical Survey of Data Augmentation for Time Series Classification with Neural Networks. arXiv:2007.15951v1
- Regan M. (2018) Github code repo: K-Nearest-Neighbors-with-Dynamic-Time-Warping
- Papers with code – time series classification

Fredrik Edin
Konsult Machine learning & data science