
Så tänker du kring marknadsföring för din startup eller hobbyprojekt
Så tänker du kring marknadsföring för din startup eller hobbyprojekt
Att starta företag som hobby- eller sidoprojekt och nå ut till potentiella kunder är svårt men det finns många aktiviteter inom marknadsföring att testa. I detta inlägg kommer Nils Fridlund som startade sin webbyrå, Sunbird, bredvid studier på Chalmers gå igenom vilka digitala marknadskanaler han rekommenderar i ett tidigt skede.
Inlägget utgår från att du har begränsat med tid, lite eller ingen tidigare erfarenheter av digital marknadsföring och att det inte finns någon större budget.
Första steget är en hemsida
För att jobba effektivt med digital marknadsföring behöver ni en hemsida.
Eftersom budgeten är begränsad kommer ni sannolikt inte kunna köpa exakt vilken hemsida ni vill.
Ni kan skapa en hemsida själv via en WordPress mall, WIX eller Squarespace.
Saknar ni IT-kunskaper helt och tycker allt med domäner och e-post känns skrämmande måste ni såklart ta hjälp med detta.
Det finns prisvärda lösningar såsom Fiverr och Freelancer där ni kan få in kunniga personer som vill skapa en portfolio.
Ett alternativ är självklart att köpa in en färdig hemsida av en webbyrå. Men många av de billigaste lösningarna blir inte bättre än det du gör själv.
Fördelen med att du driver skapandet av din egna hemsida är att du förstår din målgrupp och vad ni gör väldigt bra.
En hemsida kan man relativt snabbt byta. Men den grafiska profilen går inte lika snabbt att ändra då det finns ett upparbetat värde i den. Tipset är att lägga lite extra tid på den grafiska profilen och tonaliteten.
Summering:
- Var noga med att skapa den grafiska profilen. Den kan vara med er länge eller för alltid.
- Försök att skapa en första hemsida själv eller ta hjälp med delar. Har du en budget för hemsida kan du självklart köpa in detta.
- En One Pager eller väldigt simpel hemsida är bättre till en början än ingen hemsida alls.


Den första kunden är den svåraste
Om det är ett hobbyprojekt eller startup så utgår jag från att ni inte har någon form av kapital att investera i bolaget.
Därför kommer den första kunden i allra högsta grad bistå med budget för att återinvestera i företaget.
Den första kunden är absolut svårast. Dels mentalt men också då ni saknar budget.
Jag fick in mina första kunder via familj och därefter vänner. Jag slet hårt för att göra dem nöjda då detta blev referenser till framtida potentiella kunder och gav viss betalning.
Kan ni inte använda befintligt nätverk får ni börja med organiska kanaler inom digital marknadsföring.
Organiska kanaler kan vara en väg
Mycket av den digitala marknadsföringen kräver budget då man betalar per klick till företag såsom Google eller Facebook.
Men det finns organiska kanaler där man inte betalar per klick, exempelvis sökmotoroptimering (SEO) och inlägg på sociala medier.
Det som kännetecknar båda dessa kanaler är att de brukar ta tid att nå framgång och att det kräver en del arbete under flera månaders tid innan man får genomslag.
Eftersom sociala medier är gratis och SEO kan göras på hemsidan du skapat kräver dessa inledningsvis bara tid och tålamod.
För att stå ut i bruset behöver ni på riktigt demonstrera kunskap. Ett konkreta exempel är att ni gör som följande:
- Ni skriver hela inlägget på er hemsida (bra för SEO)
- Ni postar en summering på sociala medier och länkar till inlägget (driver trafik till webbsidan)
Dessa kanaler är långsiktiga men är även för aktiva företag en bra källa för lönsam försäljning.


Efter att du fått in de första kunderna
När ni börjat få in kunder och kapital kan ni börja spendera mer.
Inledningsvis kan ni prova antingen Google Ads eller betald annonsering på sociala medier.
- Vi rekommenderar Google Ads om det finns en tydlig definierbar tjänst som folk söker efter när de vill köpa.
- Vi rekommenderar Facebook om det finns en tydlig målgrupp som ofta söker efter det ni erbjuder.
När trafiken ökat så pass mycket och ni har ett stadigt flöde med leads kan det vara värt att förbättra hemsidan.
En hemsida som säljer dåligt brukar vara en flaskhals för tillväxt och speglar varumärket därefter. Vår rekommendation är att kontakta en webbyrå som skräddarsyr hemsidor.
Skrivet av Nils Fridlund, grundare av Sunbird som är en webbyrå i Malmö. Nils har jobbat med skräddarsydda hemsidor i WordPress, SEO och Google Ads i över 10 år. Första åren som frilansare bredvid studier.

Vill du veta mer om oss på Developers Bay?

Techkonsultbarometern 2023 - Developers Bay tar tempen på IT-konsultmarknaden
Techkonsultbarometern 2023 - Developers Bay tar tempen på IT-konsultmarknaden
Techkonsultbarometern är en årlig marknadsundersökning utförd av Developers Bay riktad mot IT-konsultmarknaden. Ambitionen är att ta tempen på hur tech-konsulter trivs och utvecklas i sina roller.
Undersökningen ger en djupare insikt i hur konsulters verklighet ser ut, vad de värdesätter i sina uppdrag och hos sina uppdragsgivare, samt hur konsultupplevelsen kan förbättras från pre-boarding till off-boarding.
Resultatet baseras på de 341 personer som svarat på enkäten. 62% av de svarande har mer än 10 års erfarenhet i sin yrkesroll och 21% har mer än 6 års erfarenhet som konsult. 78% av de svarande är enmanskonsulter, 12% är anställd i konsultbolag med mer än 20 anställda och 5% är anställda i konsultbolag med mindre än 20 anställda.
Resultatet jämförs med utfallet av Techkonsultbarometern 2022.
Några Key findings från rapporten är:
- Hög andel jobbar helt remote (34%), majoriteten hybrid (58%) och endast 7% på plats hos kund.
- De viktigaste faktorerna vid nytt uppdrag är möjligheten till hybrid, ersättningen och personerna i teamet.
- Konsulterna är mer nöjda med hanteringen av dem under pågående uppdrag och tycker att pre- on- och offboarding rutinerna kan förbättras.
- Majoriteten av konsultköparna har leverantörer som hanterar konsultadministrationen. (Två tredjedelar av konsulterna fakturerar via mellanhand och inte kunden direkt).
Ladda ner den fullständiga rapporten kostnadsfritt här.
Vill du veta mer om oss på Developers Bay?

10 reflektioner om marknadsläget för frilansare inom IT just nu!
10 reflektioner om marknadsläget för frilansare inom IT just nu!
Vi har tagit oss tiden att reflektera över hur konsultmarknaden för frilansare inom tech faktiskt ser ut just nu samt vad som är de största utmaningarna och trenderna.
Här kommer 10 reflektioner baserat på våra egna erfarenheter och data från våra system:
1. Lönsamhet är fortsatt i fokus
Vi ser att färre personer förväntas göra mer, team managers får större team och man vill få ut mer effekt av färre resurser. Det görs färre nya satsningar och mer fokus läggs på core business där bevisad lönsamhet finns.
2. Myndigheterna verkar inte bli fredade 2024
Myndigheter tog in flest konsulter tidigare i år, men där ser vi en stor skillnad. Mindre anslag, nedskärningar och förändringar intern leder till minskat intag av konsulter.
3. Hög konkurrens på resursroller
Det är hög konkurrens bland react utvecklare, backend utvecklare och andra roller utan tydlig nisch. De mer generiska rollerna är otroligt konkurrensutsatta. Detta på grund av att beställarna har mycket att välja på. För att ge perspektiv på det så har vi ca 50-60 kandidater per uppdrag för dessa roller.
4. Nya uppdrag får pressade priser
Dom som sitter på sina uppdrag sedan 2021-2022 och blir förlängda har inte blivit utsatta för prispress märkbart medan de som ska ut på nya uppdrag nu upplever prispressning i större utsträckning. Skillnaden beror på att de som redan har varit på företaget en tid är insatta i rollen och bolaget och värderas högre pga. detta.
5. Fortsatt låg personalomsättning
De som är anställda är mindre benägna att testa marknaden och hitta nytt uppdrag. Finns färre uppdrag att välja mellan och anställda tenderar att sitta kvar. Det i sin tur öppnar upp för ännu färre lediga uppdrag


6. Rekrytering har visat sig bli svårt
Rekrytering har visat sig vara svårare för företagen än vad de först trodde. Man har underskattat det faktum att alla skulle ut och rekrytera, utan att alltid ha resurser och andra förutsättningar på plats för att hantera förväntningarna. Många kunder har därför tänkt om och börjat snegla på konsultlösningar vid befintliga behov.
7. Bank, försvar, energi och AI är starka områden
Dessa områden går fortsatt bra och är stabila då de får större budgetar och satsningar på ny teknik görs. AI är något som genererar nya satsningar och startups just nu och mycket pengar läggs där. Företag har dock svårt att veta VAD dom ska göra inom AI, det är en osäkerhet där man kan behöva vägledning. Inte självklart hur och vem som ansvarar för AI-kompetens hos företag. Därför blir det nödvändigt att ha en AI-strategi. Innovation och Greenfield trendar generellt. Många personer som blivit tvungna att lämna sina trygga anställningar får möjlighet att förverkliga sina drömmar och duktig kompetens finns tillgänglig för detta.
8. Punktinsatser / definierade projekt blir vanligare
Man ser på konsulter ur ett projektperspektiv snarare än en resurs. När man har begränsad budget så väljer man att investera i konsulter för precision. Man tar in topptalanger för specifika projekt.
9. Cloud / Infra / DevOps och Data Engineering är eftertraktade
Den typen av roller är svårare att rekrytera till eftersom att de inte är lika vanligt förekommande. Därför fortsatt högt eftertraktade. Även transformationsprojekt i legacy miljöer ser ut att bli konsult tungt då den kompetensen sällan finns inhouse och det finns ej tid att rekrytera. Dessa projekt är oftast tidskänsliga och det behöver gå fort.
10. Högre krav på konsulter
Definitionen av en senior konsult har förändrats, nu förväntas 10+ år snarare än 6-7 år. Beställarna kan ställa de kraven för att de faktiskt kan hitta kandidaterna just nu. En annan sak som vi märker är att beställare förväntar sig att konsulten även har affärsförståelse och inte bara teknisk kompetens. Kommunikation och kunskapsspridning blir också allt viktigare för kunden och att det finns ett bestående värde även efter avslutat uppdrag. Det är även värdefullt att själv kunna hitta behov i organisationen och sånt som kunden själv inte har tänkt på. En sådan sak kan vara avgörande för hur långt uppdraget blir.
Vi ser också att branschspecifik erfarenhet blir allt viktigare och det är viktigt att framhäva för att bli konkurrenskraftig vid intervju. Det kanske också vara en fördel att vara öppen för att återvända till tidigare kunder. Vi ser också högre krav på hybridlösningar som är 1-3 dagar på kontoret.
Vad kan man då göra och tänka på i en mer utmanande tid som frilansare inom IT?
Här kommer några av våra bästa tips:
-
Sticka ut med din kunskap – skapa mervärde
-
Se till att vara up-to-date
-
Ha tydlig bild hur du kan hjälpa kunden med konkreta exempel
-
Var konsultmässig då kraven ökar
-
Lösningsorienterad
-
Rådgivande
-
Förståelse för förutsättningar
-
-
Flexibilitet gällande remote arbete vs arbete på kontor
-
Anpassa CV:t till olika roller
-
Intervjuträning
-
Var flexibel med priset
-
Ha en tät dialog med din kund och förmedlare
Hoppas du fann dessa reflektioner och tips värdefulla. Du kan alltid kontakta oss på Developers Bay vid frågor!
Sammanställningen är gjort av Katarina Lind (konsultansvarig) och Lubomir Struwe (säljansvarig) på Developers Bay (december 2023).

Vill du veta mer om oss på Developers Bay?

How to pick an infrastructure as code language
How to pick an infrastructure as code language
You can use several languages today to define cloud infrastructure as code. Sometimes, you have a range of languages to choose from, even for a single tool.
So what language is the right choice? My intention with this article is to give you some guidance on how to pick the right language for you.
This text intentionally focuses on language choice, and not on tool features. You will still need to consider tool features, and I will briefly touch on some of these considerations, but not do a full-blown evaluation, since that would be a too large scope.
With that in mind, here are some aspects we will look at in terms of language choice:
- Existing infrastructure code
- Consider your target audience
- Reduce cognitive load
- Speed of feedback loop
- Security considerations
- Compliance and regulation requirements
Existing infrastructure code
If you inherit a lot of infrastructure already defined with some language and tool, it may be difficult to find business value to change this to something entirely new. This will need to be weighted in when choosing a language, and even more if choosing a new tool.
Do not just jump in headfirst to convert the code to something new. It is vital to understand the reasons behind the choices for the current language and tools. This is true for any non-trivial amount of infrastructure code.
I have myself been tempted on multiple occasions to switch to something I thought would be better. However, sometimes, I backed down from that after considering several points outlined below. In some other cases, we gradually changed, and that turned out to be a pretty good choice then.
If you have an infrastructure that is set up manually, aim to import that so you can manage these resources with infrastructure as code. You need to evaluate your tool choices and see what languages it will support to generate code for.
For retaining existing infrastructure as code, you will also need to consider the ability to integrate with other tool solutions:
- CloudFormation and AWS CDK are in the same group of tools and integrate reasonably well. They do not integrate well with other tool groups (Terraform/CDKTF and Pulumi)
- Terraform and CDKTF is in the same group of tools and has some (read) integration with CloudFormation, and thus indirectly with AWS CDK.
- Pulumi has some (read) integrations with both Terraform and CloudFormation, and thus indirectly with AWS CDK and CDKTF
This is for integration with existing provisioned infrastructure, e.g. referencing resources in existing stacks or state storage. A more tool agnostic approach is possible as well. For example, by sharing resource references via AWS Systems Manager Parameter Store, then the underlying tools that provisioned a resource do not matter.
Consider your target audience
Who will define infrastructure? Are the application developers also responsible for the application infrastructure? Or is there a platform or operations team that handles the infrastructure?
Are there multiple groups, e.g. application developers handle “just enough infrastructure” and the more complicated parts by a platform team?
There may not be a single choice here, as the needs for each group to work efficiently with the infrastructure definitions may be different.
An application development team may work better with a different language than a platform team, since the way of working and tools used may be different.
Do not just jump in headfirst to convert the code to something new

Reduce cognitive load
Do you have an application development team that works with Java, and also will be responsible for application infrastructure? Then it may make sense to pick Java to define the infrastructure, as that may reduce the cognitive load – the amount of things you need to keep track of and handle to do the work.
If the application team does very little or no infrastructure, and a separate team handles the infrastructure which does not work with Java regularly, then a different choice may be better.
If an application development team handles some of the infrastructure, and another team the rest, then each team might benefit from different language choices.
When we talk about a cognitive load for different languages, it is not just the complexity of the language itself, but also the runtime environment and the surrounding tooling.
Which tools should we use for Python package management, virtual environments? What linters and test tools to use with Typescript, and what are the configuration settings for each of those? Are we using Gradle or Maven with Java? Should we runt terragrunt with terraform, and are we setting up tflint, tfsec or some other tools? Do we use Sceptre with CloudFormation?
If a language is not used daily, then the cognitive load may be significant each time you need to do something. In these cases, it is important to consider the languages themselves, the runtimes and the surrounding tools. Also, not just the happy day scenarios, but when things go wrong as well.
If you work with a certain language daily, then the additional cognitive load will not be that much, even if the language and tooling setup may be complex. You already manage that.
Note that reducing cognitive load does not mean you should always pick languages and ecosystems that a team already knows. If you expect the team to work with a language daily or with high frequency, it could be ok to use a new language and ecosystem. It is ok to learn something new, as long as you keep using it regularly.
Cognitive load and complexity of infrastructure
The cognitive load aspect load aspect may also come into play for the actual infrastructure definitions as well.
If you work on infrastructure that changes with about the same frequency as the application itself, then the added cognitive load may not be that high.
There may be infrastructure that does not change much, like virtual networks and VPN connections. Each time you actually need to change something here, there may be some additional cognitive load if you do not work with the networking daily. Thus, the life cycles of the infrastructure may affect the cognitive load.
What does this mean? It means static infrastructure that seldom changes benefit from languages that are easy to read and get into, even if you are not that familiar with the code. It also means that the language does not need to support complex logic, and a strictly declarative language may be just fine.
Infrastructure definitions which changes more often and may have more dynamic definitions, benefit from more expressive languages. The underlying representation can still be declarative.
In fact, many of the tools that support languages that are not strictly declarative, like AWS CDK, CDKTF, Pulumi and CDK8s, generate declarative definitions under the hood.
But for reading and understanding the infrastructure definitions, a declarative language may be better for static infrastructure, which does not need any complex logic to be defined.
Of course, supporting multiple languages may add complexity as well.
Cognitive load and package/module management
Most infrastructure-as-code tools have some sort of module/package management support, to handle re-use and defining suitable abstraction layers for the users of a module/package.
Using those is part of the expected for each language choice. However, if you decide to support multiple languages with packages, then you will add cognitive load for the package maintainers.
For example, if you want to support Typescript, you typically need to deal with npm, with Python you deal with PyPi, Java you use Maven, C# you use NuGet, etc.
Cognitive load and (idiomatic) language use
If a tool support multiple languages, that means there are some restrictions on packages and/or code to work with all supported languages.
That can also be more apparent if you pick a language that may not be officially supported or have first class support, but have a supported runtime – such as the JVM or .NET runtimes.
Any such deviations might add to the cognitive load as well. Of course, the extent to which a language is used with the specific tool choice is a consideration as well. How easy is it to get help and find examples for a particular language?
Cognitive load across tools
Mixing multiple tool and tool families is certainly possible, but may add cognitive load as well, regardless of language. It is somewhat fuzzy at times.
- CloudFormation and AWS CDK is in the same family in that the underlying representation used is CloudFormation, although AWS CDK introduces a few new concepts in the mix
- Terraform and CDKTF in the same family in that the underlying representation used is Terraform, although there are a few new concepts with CDKTF also.
- All CDK tools (AWS CDK, CDKTF, CDK8s) share some common elements as well
- There are some similarities across all tools that use programming languages as well, including most of the supported languages
- Both CDKTF and Pulumi have some support to use AWS CDK components in the code
Speed of feedback loop
It is slow to provide infrastructure, much slower than just starting an application most times. This is something to keep in mind.
Mostly, the speed of the language execution itself is not a bit factor. It is often more about the speed of the tool itself rather than the language used.
I did some experiments with AWS CDK and the time to generate the underlying CloudFormation was about the same regardless if I used Go, Typescript or Python for example.
Since there is an extra step to generate CloudFormation, or Terraform with CDKTF, there is some extra time added compared to using CloudFormation or Terraform directly. The extra time here may not be a good enough reason to avoid it.
Good type checking and tooling support in IDEs or editors can shorten feedback loop, if that exists for a language. This is typically an advantage for many regular programming languages.
Security considerations
Is the use of a particular language, its runtime and associated tooling secure? More versatile languages and tooling comes with additional risks to expose the infrastructure definitions to troublesome pieces of code.
How trustworthy are any imported packages/modules and are they locked to a specific release? Do you require fetching data from outside to import when you build your infrastructure?
What packages should be safe to import and use? Should there be guidelines and checks for how a specific language is used and what can be imported?
Again, the language runtime and the surrounding ecosystem are important to review and decide on safe usage patterns.
Compliance and regulation requirements
Your line of business may have compliance requirements that will affect language and language ecosystem choices. This is something to look at, in particular if you are introducing an entirely new language and ecosystem to the business.
Any issues are more likely around the ecosystem and tooling and practices around these than the language itself.
This also includes any potential licensing issues, although this is more likely to be a potential issue for any specific tooling or 3rd party packages used than for the language itself. Again, this may require some extra effort in particular if you are introducing a new language and ecosystem to the business.
An example
Setting
Let us take a fictional example. The company myexample.com has about a dozen development teams and a platform team. There are multiple solutions and services these teams work on. Some services are built with Typescript, others are built with Go.
Each development team handles infrastructure close to the application solution, e.g. services as AWS Lambda, DynamoDB, ECS Fargate, etc. They have separate accounts for development, test and production in most cases, although some environments have shared networking as well.
Networking setup, IAM, backups and baseline security setup are handled by the platform team, and they also have a mix of people that work with the infrastructure setup daily, as well as more seldom.
Teams use a mix of Serverless framework, CloudFormation and a bit of AWS CDK for their infrastructure and application deployment. There are also resources that have been set up manually. For AWS CDK, there are infrastructure resources set up in Typescript and Python.
Some teams have automated deployments, some have manual deployments.
Choice example
Since development teams work daily with Typescript and Go, it makes sense that those that use AWS CDK with Typescript can continue with that. It may make sense to use Go also for team infrastructure, if there are teams that use Go daily, but not Typescript.
Right now AWS CDK with Python may be an outlier, and potentially drop that and look at converting to Go or Typescript.
Platform team may benefit from having relatively static infrastructure in a more declarative format, e.g. CloudFormation YAML, Terraform HCL, or Pulumi YAML (or CUE). When a programming language would be used, one of Typescript or Go would be likely candidates. Go’s ecosystem and tools may be simpler to grasp and keep control of, and fewer 3rd party dependencies. But this would also depend on other tasks that the platform team is doing.
Technically AWS CDK, CDKTF and Pulumi all support Go and Typescript. If the platform team would build re-usable components or modules for the other teams, they would need to support multiple languages. For AWS CDK, that would mean in practice to write these components/modules in Typescript – or CloudFormation with some Typescript. It could be in HCL with some typescript or all in typescript. For Pulumi it should be possible with any of the languages.
I have avoided picking any specific tools here, since there would be a need to more in depth on the situation at myexample.com.
Summary
In this article I have tried to point to some considerations when picking a language for infrastructure as code, without going into much specifics for each tool.
Most of the text deals with cognitive load, which I think most times is not fully appreciated for the intended target audience of the infrastructure definition work.
One tool or language does not fit all, and sometimes it may be better to have a limited selection rather than a single choice, or a total free-for-all.
For example, I have worked with a few projects where AWS CDK using Typescript has been the tool and the language of choice for everyone. Sometimes that worked reasonably well, in others it did not work out. The threshold to work with the language and ecosystem, as well as the underlying tools, were too high for some people, and the maintenance suffered because of that.
Do you have any experiences yourself with language choices for infrastructure-as-code? What are your thoughts?
Read more articles written by Erik Lundevall-Zara here.
Vill du veta mer om oss på Developers Bay?

Developers Day 2023 blev en succé!
Sveriges första utvecklargala - Developers Day 2023 blev en succé!
Under Developers Day 2023 hyllades utmärkande prestationer i techbranschen med flertal värdiga nominerade samt pristagare i nio olika kategorier.
Den 13:e september på programmerarens dag sammanförde Developers Day profiler, experter, innovatörer och visionärer inom tech sektorn för att uppmärksamma insatser och prestationer som är värda att hylla lite extra.
Under kvällen delades prestigefyllda priser inom nio olika kategorier ut.
Årets Utvecklare: Gick till en person med djup teknisk kompetens som både löser komplexa problem med robusta lösningar och även sprider sin kunskap till andra utvecklare. Grattis, Jonas Brandvik!
Årets Open Source Contributor: Gick till en person som dedikerat och kontinuerligt bidrar till open source med sin kunskap och sina värdeskapande commits.
Grattis, Joel Arvidsson!
Årets Inspiratör: Gick till en person som lyckats skapa nyfikenhet, nya insikter och inspirerat andra till att tänka och agera på nya sätt inom tech.
Grattis, Fredrik Björeman & Kodsnack!
Årets Utbildare: Gick till en person som på ett professionellt sätt bidrar med kvalitativ kunskap och lyfter kompetensnivån inom tech.
Grattis, Muhammad Ahsan Ayaz!
Årets Innovation: Gick till ett företag som är både nytänkande och samhällsutvecklande.
Grattis, Gaia Gen!
Årets Frilansare: Gick till en person som är en förebild för andra frilansare både med sitt sätt att agera i uppdrag hos kunder och med sin generösa inställning hjälper andra frilansare att bli framgångsrika.
Grattis, Erik Hellman!
Årets CTO: Gick till en person kan balansera teknisk expertis med strategiskt tänkande, ledarskapsförmåga, effektiv kommunikation, anpassningsförmåga samt affärsmannaskap för att driva företagets framgång.
Grattis, Tobias Palmborg!
Årets IT-konsultbolag: Gick till ett IT-konsultbolag som under flera års tid bevisat att man är attraktiv och värdeskapande hos såväl medarbetare, kunder och samarbetspartners.
Grattis, B3 Consulting Group!
Hero’s Journey Award: Gick till en inspirerande individ som har övervunnit otaliga hinder på sin resa inom tech branschen och strävar efter att inspirera andra på vägen. Grattis, Khosiyat Sabir!
“Stort tack för ett jättefint ordnat event! Så roligt att träffa så många inspirerande personer inom branschen” – Katarina Carlén Lundqvist, Kommunikationschef B3 Consulting
Tack till juryn och kvällens konferencier:
Vi vill ta tillfället i akt att uttrycka vårt djupa tack till juryn, bestående av Anna Leijon, Peter Kolnhofer, Elin Ahldén, Jonas Wallenius och Erik Hedberg. Deras expertråd och noggranna bedömning av alla nominerade spelade en avgörande roll i att välja de värdiga vinnarna av årets utmärkelser. Ert engagemang och expertis är ovärderlig.
Vi vill även tacka vår utmärkta konferencier, Johan Öbrink, som med sin skicklighet, timing och charm ledde oss genom en minnesvärd kväll med skratt, spänning och inspiration.
Tack till våra sponsorer:
Utöver detta vill vi rikta ett stort tack till våra sponsorer – SALT, True, Qinshift och Developers Bay. Ert stöd och engagemang har varit avgörande för att göra denna galakväll möjlig.
Developers Day 2023 var en enastående framgång som hyllade tech-världens hjältar som ofta jobbar i det tysta. Dessa utmärkelser erkände framstående prestationer och innovationer som förbättrar samhället och våra liv dagligen.
Intresserad av att delta på nästa års gala? Anmäl ditt intresse här redan nu!
För ytterligare information och samarbeten, vänligen kontakta eventansvarig Maria Windna / hello@developersday.se
Om Developers Day
Developers Day är en unik gala som syftar till att hylla utvecklare och techprofiler som är hjältar inom tech-industrin. Denna galakväll kommer att fira och uppmärksamma dessa yrkesgrupper som ofta jobbar i det tysta för att skapa fantastiska tekniska lösningar och innovativa produkter som förbättrar våra liv.
Vi öppnar för nomineringar till Developers Day 2024 inom kort.


Why Infrastructure-as-Code Matter to You, Even If You Are Not a Hotshot Developer
Mia
Skriven av Erik Lundevall-Zara
What is the deal with infrastructure-as-code, why does it matter to you?
Infrastructure-as-code, governance-as-code, and other “as-code” terms all deal with a set of desirable properties and outcomes. These properties and outcomes include getting consistent, reliable, repeatable solutions of some kind – with (relatively) fast feedback and delivery.
If you run business solutions at a cloud provider such as Amazon Werb Services (AWS), this will matter to you.
For infrastructure-as-code, this typically means to quickly and reliably set up and update (cloud-based) infrastructure. This infrastructure is the IT foundation that many business solutions depend on to run in a good way.
Thus it is a benefit to handle this consistently and reliably. If business expands or disaster strikes – also have the whole process repeatable and quick.
What as-code means
The term “as-code” in infrastructure-as-code may lead you to think it is about writing computer software to build infrastructure.
While this is certainly one way of doing it, the term “as-code” is a kind of abbreviation of “where we use good software engineering practices to produce great outcomes for the business.” But infrastructure-where-we-use-good-software-engineering-practices-to-produce-great-outcomes-for-the-business is a bit of a mouthful, so the short form “as-code” stuck instead…
What kind of good software engineering practices are we talking about here?
- Provide a human-readable and precise description, without ambiguity
- Keep track of changes in these descriptions, so we know what changed and who changed it
- Keep a version and release history of changes, with meaningful labels
- Allow us to see what state of the descriptions were at a specific time or associated with a specific label
- Be able to perform tests against an infrastructure description, to validate key elements of the descriptions
- Have computer software that can parse and execute the content of the infrastructure descriptions, to produce desirable outcomes
- An organizational structure that supports a way of working that fits with these concepts
Note here that only the second to last bullet point mentions computer software. Instead, it is mainly about practices that allow us to keep track of what we do efficiently. In addition, It is also about to allow the use of software tools to make this type of work more efficient, faster and eliminate human errors as much as possible.
One type of description I mention is certainly programming language code, as it has some desirable properties. But it does not have to be that.
For the most part, it will boil down to a textual infrastructure description, since this is something both humans and computer software tools may handle reasonably well.
Another vital part, sometimes overlooked, is that working with these tools and processes needs to be supported by the way people work and organize. If not, it is going to become messy no matter what.

What tools to use with as-code solutions
A vital tool is a version control system (VCS). It is also called a software configuration management (SCM) tool. Today, the most popular tool in this space is probably git, but there are many other tools also. Multiple hosting services can help you store and manage data using git – three prominent ones are Github, Gitlab, and Bitbucket.
Any tool that can create and edit text is valid to write the infrastructure descriptions. These tools could be anything from Notepad on Windows to more advanced tools, such as Jetbrains Intellij IDEA.
A useful set of tools that comes up a lot are those associated with Docker, which is a way to package (application) software to be provisioned to the infrastructure.
Tools to describe my infrastructure
Vital tools to work with infrastructure-as-code are the tools that understand the infrastructure descriptions. The examples here focus on Amazon Web Services (AWS) cloud infrastructure. Tools such as Terraform, Pulumi, and CDKTF work with other providers also. Common tools include AWS Cloudformation and Terraform, which uses textual configuration descriptions to describe the infrastructure. These can go into quite a bit of detail, which means they are very versatile. However, these tools can also get complex to use.
Simpler tools include AWS Copilot and AWS AppRunner. These tools focus on a more limited set of use cases for cloud infrastructure, but on the other hand, they are also overall simpler to use.
We also have tools that involve actual programming language code, such as AWS Cloud Development Kit (AWS CDK), Pulumi, and Cloud Development Kit for Terraform (CDKTF). All these allow infrastructure to be defined and described using programming languages. For developers who are used to coding, this can be great.

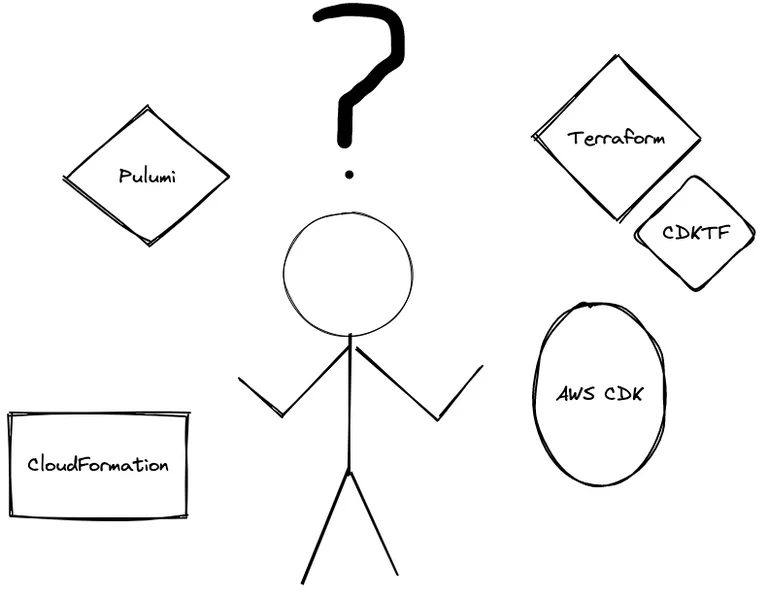
What tools should I pick?
I would argue that for the tools that describe the infrastructure, there may be four groups of people:
- Developers, who only want to care about application solutions, not the infrastructure it uses
- Developers, who want to care about the infrastructure
- Operations and sysadmins people, who care about the infrastructure, and does not consider themselves developers
- Other people
If you have people that fit all bullet points, you could pick any of these tools. The CDK + Pulumi tools should have some persons that fit the developer-who-cares-about-infrastructure to be a good choice. They can provide support for the other groups using these tools.
Operations and sysadmins people may consider AWS Cloudformation and Terraform as options, unless they want to dive into learning programming more in-depth.
Developers who mainly want to focus on application solutions may be served better by AWS AppRunner and AWS Copilot if they do not have the support from other groups – if their use cases fit these tools. This is probably the starting point for the “other people” group also if the other groups are not there to support them. However, there is still a need to understand the application software to run, so the “other” group will need some additional support – or prepare to learn some of the skills of the other groups.
What to do next
Start with tutorials for the simpler tools, like AWS AppRunner or AWS Copilot – the latter can even deploy AppRunner solutions as well. Pick a hosting service for version control system software, and get familiar with it. I would suggest starting with Github, even if this is not what you will use in the end. Github is the largest hosting service on the market, so there is plenty of example for it. Plus, you can sign up for free and use it.
Read more articles written by Erik Lundevall-Zara here.
Missa ingenting.
Prenumerera på vårt nyhetsbrev. Vi lovar att bara skicka relevant information och aldrig spamma dig.

Developers Day 13:e september
Nu lanseras galan Developers Day för att hylla personer och bolag i tech branschen
Developers Day äger rum på Programmerarens dag den 13:e september, en dag som firas över hela världen för att hedra utvecklare och deras bidrag till teknologins utveckling. Platsen för galan är K-märkt i Garnisonen för att hylla personer, företag och initiativ som har gjort framstående insatser inom tech-industrin. Huvudarrangör är Developers Bay, agentur och community för frilansare inom IT.
Under galan kommer utmärkelser att delas ut i olika kategorier som “Årets CTO”, “Årets Utbildare”, “Årets Utvecklare” och “Årets Impact Initiativ”. Vinnarna kommer att utses av en jury bestående av ledande personer inom tech-industrin och offentliggöras under galakvällen.
“Vi är glada över att kunna skapa en möjlighet att hylla dessa inspirerande personer, företag och initiativ som har gjort en verklig skillnad inom tech-industrin”, säger eventansvarig Maria Windna. “Denna galakväll är ett tillfälle för oss att visa vår uppskattning för enskilda individer och deras bidrag och ge dem det erkännande de förtjänar.”
Developers Day kommer att vara en festlig tillställning med trerätters middag, god dryck, lightning talks och underhållning. Bland gästerna kommer det att finnas ledande personer inom tech-industrin, investerare, entreprenörer och andra influencers inom tech-sektorn.
Biljetter till Developers Day finns tillgängliga nu på www.developersday.se. Det kommer att bli en kväll att minnas med glädje, så se till att säkra din plats idag och delta i firandet av tech-profiler och innovationer på K-märkt, Garnisonen i Stockholm den 13:e september.
Ansvarig: Maria Windna / hello@developersday.se
Vill du veta mer om oss på Developers Bay?

Sveriges Radio
Sveriges Radio tecknar ramavtal med Developers Bay inom fyra olika områden
Developers Bay har vunnit Sveriges Radios upphandling som ramavstalsleverantör av kompetens inom IT. Avtalet gäller de kommande två åren inom områdena “Apputveckling”, “Systemutveckling”, “Uppdrag/förvaltning” samt “Digital produktdesign (UX/UI/Tjänstedesign)”.
“Vi på Developers Bay är mycket glada och förväntansfulla för att få möjligheten att matcha rätt konsulter till Sveriges Radio de kommande åren och upprätthålla ett kvalitativt och hållbart samarbete.” säger Inti Basantes, ansvarig för Offentlig sektor hos Developers Bay.
Developers Bay är en agentur och nätverk för Sveriges främsta frilansare inom tech med målet att skapa den bästa konsult upplevelsen för både konsulter och kunder.
Kontaktperson: Inti Basantes / inti@developersbay.se tel. 0738 730383
Vill du veta mer om oss på Developers Bay?

My Morning Routine - How Successful People Start Every Day
Mia
Skriven av Erik Svensson. Inspirerad av Benjamin Spall and Michael Xander.
Stapplar du dig ur sängen på morgonen och känner dig överväldigad inför dagen framför dig?
Detta är inget bra sätt att starta en morgon om man ska lita på Benjamin Spall och Michael Xander, författarna av denna bok. Deras forskning visar att en målmedveten och omsorgsfull morgon gör dig redo för dagen framför dig. Förutom förslag på användbara morgonritualer tas även tips från framgångsrika människor såsom OS-medaljörer och VD:ar i framgångsrika bolag upp för att ge inspiration till att utveckla din egen rutin.
One-size-fits-(almost)-all
Att stressa igenom de första timmarna på morgonen hjälper dig inte att möta dagens utmaningar, så långt är vi nog alla överens.
En morgonrutin kommer inte i en one-size-fits-all. Vad som funkar för en annan kanske inte är rätt för dig. Ditt jobb, din personliga rytm eller om du har barn styr hur du startar din dag och hur du kommer att möta dina dagliga sysslor eller inte.
Kort och gott: den första timmen på dagen, när den nu inträffar, sätter tonen för resten av dagen.
Att snooza eller inte snooza
Om du är en av dem som ej klarar av att vakna tidigt för att utföra dina viktigaste sysslor innan dagen startar så rekommenderar då författarna att steg för steg nå ditt mål för att ge rum för just detta. Ställ väckarklockan fem minuter tidigare varje vecka och upprepa detta tills du har tid att utföra din tänkta morgonrutin.
– För att tala om motsatsen till denna teknik så gäller det självklart det gamla(?) ordspråket: “you snooze you lose” – genom att använda denna funktion på ens väckarklocka så blir man garanterat mer trött och seg än första gången larmet går. Välj alltså hellre att ställa klockan tidigare än att senarelägga ditt uppvaknande nästa gång.
Skulle nu den inkrementella taktiken fallera eller frestelsen för snooze ta över finns det två enkla sätt som garanterar ett tidigt vaknade. Skaffa barn eller hund – eller varför inte båda?

Att göra-lista
De av oss som kategoriserar sig som morgonmänniskor tycker att de arbetar mest produktivt under dygnets första timmar. Oavsett om du hör till den gruppen eller inte ska denna tid alltid präglas av fokus och en klar intention.
Skapa en att göra-lista på kvällen inför morgonen därpå. Genom att skriva ner saker så frigör du minnet (tänk datorns motsvarighet – RAM) och kan på så sätt slippa tänka på vad som ska göras härnäst. Författarna rekommenderar vidare att begränsa denna lista till 5-6 saker. Välj de mest kritiska sakerna att göra först och senarelägg mindre tankekrävande uppgifter såsom planering av telefonsamtal och möten till senare på dagen.
– Här kan jag själv rekommendera Google tasks som fungerat utmärkt för mig. Jag får möjlighet att se mina uppgifter i både mobilen och datorn men även att enkelt skriva ned saker så fort de kommer upp i tankarna. Perfekt för bland annat kundmöten och när man är ute på uppdrag!
Att inleda morgonen med att kolla mejl är generellt ingen god idé. Detta överlåter din kontroll till att i stället besvara andra personers frågor och behov. Däremot väljer Rafael Reif, presidenten för MIT, att göra motsatsen och menar att detta låter honom svara på viktiga meddelanden som kommit in under natten genom att snabbt kolla igenom sin inkorg. Meningarna går således isär men så länge vi inte har en position med samma globala ansvar som Rafael så kan vi nog ägna vår morgonstund till att fokusera på oss själva – deal?
Svettig morgonrutin
Att lägga in ett träningspass i din morgonrutin är ett utmärkt val, vissa föredrar hellre att träna senare på dagen men återigen gäller det här att hitta något som passar ens egna dagliga schema. Håll dig till det som funkar för just dig menar författarna. Finessen med att välja ett träningspass i ens morgonrutin ger, oavsett dagens utmaningar, en bekväm känsla av att man säkrat sin träning för dagen och förhoppningsvis känns alla utmaningar under resten av dagen som en baggis.
Ytterligare ett förslag till din arsenal är meditation. Det förbättrar koncentrationen, höjer fokus och sänker stressen men hjälper dig även att sova bättre. Om du inte gillar den traditionella meditationen kan du även använda guidad meditation. Du kan också öva att vara närvarande när du exempelvis kokar vatten eller brygger kaffet och låta tankarna vila – genom att släppa annat för stunden ger du tankarna en paus och du får alla tänkbara fördelar som nämnts ovan, bra eller hur? Meditation kan ses som ett sätt att sätta problem i perspektiv och framhäva tacksamhet för allt som livet har att erbjuda.
Sugen på något nytt? Bli medlem i Developers Bays nätverk för frilansare idag! https://developersbay.se/frilansare/

Ordning och (o)reda
Alla har inte lediga kvällar, men om du brukar tillbringa kvällarna hemma välj då att använda tiden klokt i stället för att slötitta på TV. Vissa föredrar att arbeta på natten, men även om du är en nattuggla bör du använda en rutin innan läggdags, mer om detta i nästa stycke. Exempel på fördelaktiga rutiner kvällstid inkluderar: välja ut kläder för nästa dag, göra i ordning sina träningskläder, skriv att göra-listor i slutet av arbetsdagen och granska nästa dags schema.
– Här anser jag att det gäller att inte överväldiga sig själv, kollat enbart på nästa arbetsdag. Att vakna upp till ordning ger lugn, välj därför att städa upp innan du lägger dig och förbered kaffebryggare – om du jobbar hemifrån. Den tid du spenderar med att varva ner på kvällen öppnar möjligheter att fokusera de tysta morgontimmarna på saker som verkligen betyder något, mer om detta längre ned.
En god natts sömn
Något annat som också kanske känns självklart men som är värt att poängtera är vikten av en god natts sömn som ger energi för morgonrutiner och tillåter dig att maximera din dag. Hur uppnår man detta? Enkelt, genom att sova tillräckligt. Något som jag själv tummat på rejält – speciellt när det finns så mycket jobb man enkelt kan bränna av just på grund av tillgängligheten till telefonen – är att hålla sovrummet en digital frizon.
Jag är säker på att alla redan hört detta, men det blåa ljuset är boven i dramat. Den påverkar vår dygnsrytm (circadian rhythm) och aktiverar vår kropp då den misstar ljuset för dagsljus. Vill du läsa mer om detta så rekommenderar jag boken Why We Sleep av Matthew Walker. En bra milstolpe som kan underlätta är att hinna med “midnattståget” som författarna kallar det d.v.s. somna innan midnatt.
Laget före jaget
När familjen och främst barn kommer in i ekvationen är det lätt hänt att det tummas på rutinerna eller att de helt enkelt kastas bort totalt. För er med barn som läser detta så finns det mycket att vinna på att vakna innan barnen för värdefull egentid enligt författarna. När väl resterande familj vaknar så gäller även här en digital frizon. Hur många gånger har man inte hört föräldrarna säga att uppväxten av barn gick för fort – tänk då hur fort det går när även telefonen tävlar om din uppmärksamhet?
Om du inte redan är såld på detta kan det vara värt att nämna att bland annat en av Twitters medgrundare umgås med sina barn en timme innan jobbet – kanske är detta en rutin värd att prova?
Tillbaks på ruta ett
Varje morgon erbjuds möjligheten att påbörja ett oskrivet blad och även en nystart. Genom att just ta hand om dina egna behov innan allt annat på morgonen ger du dig lugnet som behövs för att kunna svara på dagens alla utmaningar. Din egentid på morgonens s.k. tysta timmar är både värdefull och bidrar också till ditt välmående.
– Här kan jag själv tycka att just tanken att få klart en riktigt klurig uppgift eller ett tungt träningspass innan dagens ens börjat för omgivningen är svårslagen. Det ger även ett försprång och det är inte helt ovanligt att dagens sysslor redan är färdiga innan lunch på grund av ett uppbyggt momentum.
Detta summerar boken “Morning Routines” men även fördelarna med just rutiner i ett bredare perspektiv. Avslutningsvis kommer här ett citat från Thomas Carlyle som sägs ha kopplingar till rutiner:
“A man without a goal is like a ship without a rudder.”
Glöm inte heller att bli medlem på https://developersbay.se/frilansare/ för att ta del av de senaste uppdragen som frilansare!
Hälsningar, Erik
Vill du veta mer om oss på Developers Bay?

How to use Azure Container Registry in Kubernetes
Mia
Written by Mehrdad Zandi
What is Azure Container Registry (ACR)
Azure Container Registry (ACR) is a private registry service for building, storing, and managing container images and related artifacts like as Dockerhub. ACR is used specially by Enterprises which don’t want to have their containers on a public share.
ACR comes in three pricing tiers: Basic, Standard, and Premium. The main difference between them is the amount of included storage and the number of webhooks you can use. Additionally, the premium tier supports geo-replication. This means that your images are still available when a data center goes down.
In this post, I will describe how to create ACR, how to upload images to ACR, and how to pull images from ACR by configuring your Microservice and Azure Kubernetes cluster to run them in your Kubernetes cluster.
Prerequisites
- A GitHub account. Create a free GitHub account, if you don’t already have one.
- An Azure DevOps organization and a project. Create a new organization and/or a new project, if you don’t already have one.
- An Azure account. Sign up for a free Azure account, if you don’t already have one.
Create Azure Container Registry in the Azure Portal
I have described in my post Azure Container Registry (ACR) , how to create and how to push image to ACR. You can create ACR by looking to this post.
Here I have created ACR with name: mehzanContainerRegistry with Resource Group: mehzanRSG, in Region: Sweden Central.
Pushing Image to ACR
You have two alternative to push image to ACR:
- Alternative 1: importing the image from Dockerhub.
- Alternative 2: uploading it from a CI/CD pipeline.
I am going to describe the both alternatives in this post
Alternative 1: Import Image from Dockerhub into ACR
To import the image, use the following Azure CLI commands: (run az login first and then az acr import ..)
The first line logs you into your Azure subscription and the second one takes the name of your ACR (name should be lowercase), the source image from Dockerhub, and the image name which will be created in ACR .
In here I have taken the productmicroservice image from my Dockerhub: docker.io/mehzan07. (Your image should be exist in the your Dockerhub, otherwise you can push it from your local).
If importing is succeeded then navigate to your ARC registry in the Azure portal and select Repositories, then you can see productmicroservice (as shown in the following figure). If you double click it shows tag: latest.
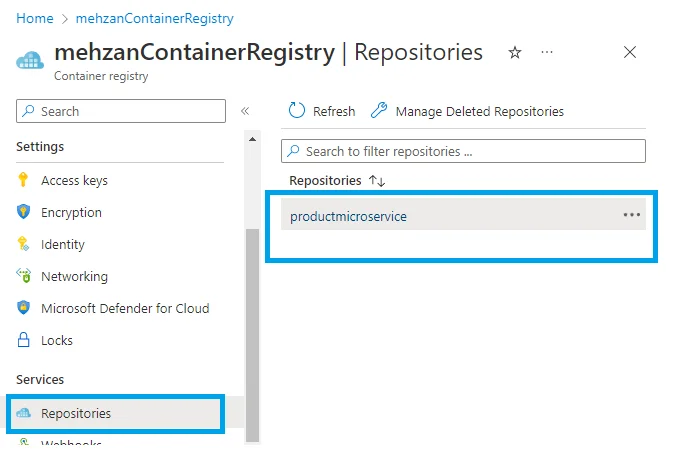 Importing Image: product microservice from Dockerhub to ACR
Importing Image: product microservice from Dockerhub to ACR
Create Azure Kubernetes Service (AKS)
You have to create an Azure Kubernetes Service (AKS), To Create AKS look to my post: Azure Kubernetes Service (AKS)
I have created AKS with name: microservice-aks with Resource group: mehzanRSG in Region: Sweden Central ( in the same Resource group and and same Region for ACR which I have created in this post).
Note: I haven’t create any Services and Progress yet, I shall create this later on.
Pulling Image from Azure Container Register to Kubernetes (aks)
To pull this image from kubernetes we should authorize Kubernetes to pull images from ACR.
Kubernetes is not authorized to pull the image. This is because ACR is a private container registry and you have to give Kubernetes permission to pull the images.
Allowing Kubernetes to pull ACR Images
To allow Kubernetes to pull images from ACR, you first have to create a service principal and give it the acrpull role.
Service principals define who can access the application, and what resources the application can access. A service principal is created in each tenant where the application is used, and references the globally unique application object. The tenant secures the service principal sign-in and access to resources. For more about Service Principal.
Use the following bash script to create the service principal and assign it the acrpull role.
1- Run the following script on Azure CLi command (start from portal):
Where the mehzancontainerregisry is the ACR name which we have created in the beginning of this post.
Note: If running of copy of this script is not worked then you should first copy and paste it to notepad and then take from there to run in the Azure CLI.
If it is succeed then output will be like as following:
Service principal ID: f8922aa7-81df-48a5-a8c6-5b158edb6072
Service principal password: oDm8Q~eVBH-15mE25t3EIqyTt0pc87UWmhVURaIM
Save these Service principal ID and Service principal password: and use them in the next step (in the following).
2- Next, create an image pull secret with the following command in the command line:
where docker- server value (mehzancontainerregistry.azurecr.io) is ACR Service and it is created with creating of ACR in the beginning. namespace: as default, docker-username: the Service principal ID value and docker password f Service principal password value from the step 1.
If it succeed the output will be: “secret/acr-secret created “
namespace value can be found from Ks8: dashboard as shown in the following figure:

3- Use the Image Pull Secret in your Microservice (productmicroservice)
After the image pull secret was created, you have to tell your microservice to use it. I have used the values.yaml file (under charts:productmicroservice) for values, as following code:
I have build image and pushed to my dockerhub before importing of image. The Source code can be found in my Github.
If you used a different name for your secret in the kubectl create secret docker-registry, then you have to use your name instead of acr-secret.
4- Copy the following yaml in somewhere in your local machine and give a file name (like as : acr-secret.yml)
And run it in the following kubectlcommand as follow:
I have saved the script in acr-secret.yml in the path C:\Utvecklingprogram\Kubernetes\
And run it as following command line from my local machine
If it succeed the output shall be: pod/productmicroservice created
where name: productmicroservice is the pod name of productmicroservice in the kubernetes (shall be seen in KS8: dashboard) and containers: name: mehzancontainerregistry is the ContainerRegistry name we have created in Azure (the name should be lower case). The image: mehzancontainerregistry.azurecr.io/productmicroservice:latest is the image in the Container Registry Service from Azure which we have imported from my Dockerhub.
Test the pulling image from Kubernetes (aks).
Connect to the K8s dashboard (by starting Octant from your local machine) If you have not installed Octant look to the my post: azure-kubernetes-service-aks
Start Octant from your local machine(start menu) and click on the Workloads: Pods, the following shall be displayed:
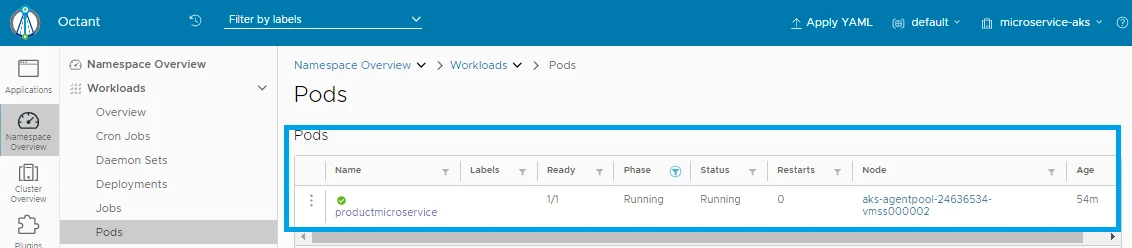 Pod: productmicroservice is pulling from ACR and Running.
Pod: productmicroservice is pulling from ACR and Running.Look to the Config and Storage: Secret:
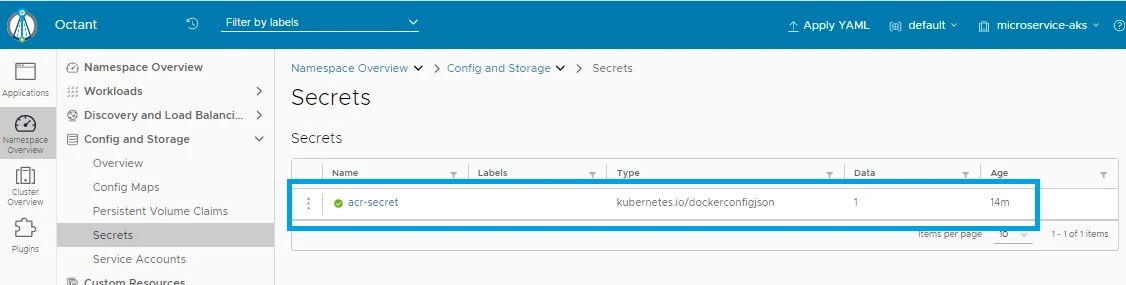
Config and Storage: Secrets: acr-secret is ok
As you see the acr-secret is created in your KS8 service.
Look to the Events:
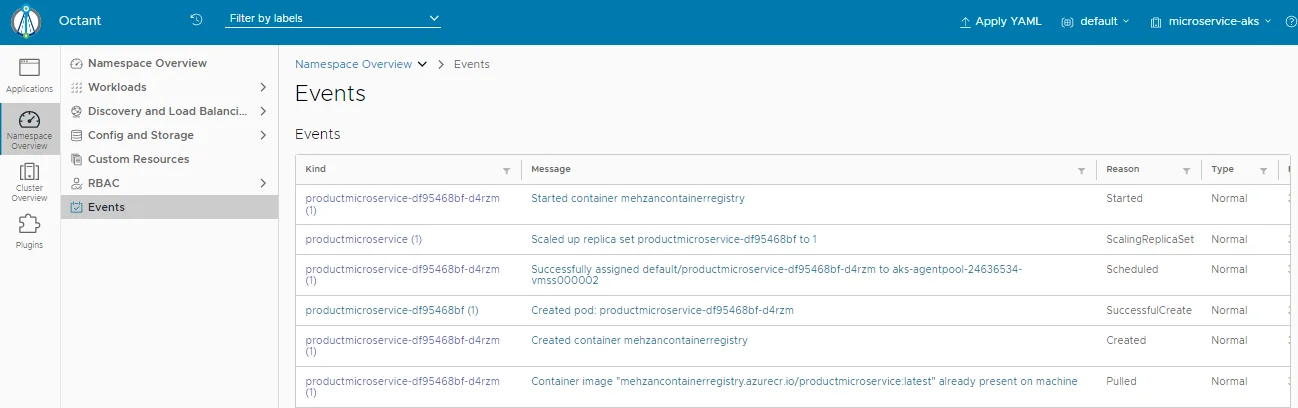
Event shows pod: productmicroservice is created
If we check the Services on the KS8: dashboard then we see this part is empty, because we have created only a kubernets (microservice-aks) without any “Service and Ingress”. Now we want to have Service and test application (productmicroservice). We can create Service And Ingress as described in my post: Azure Kubernetes Service (AKS) In the section: deploy the first Application.
Now go to the KS8 dashboard : Discovery and Load Balancing: Services then you can see that productmicroservice is created as following image:
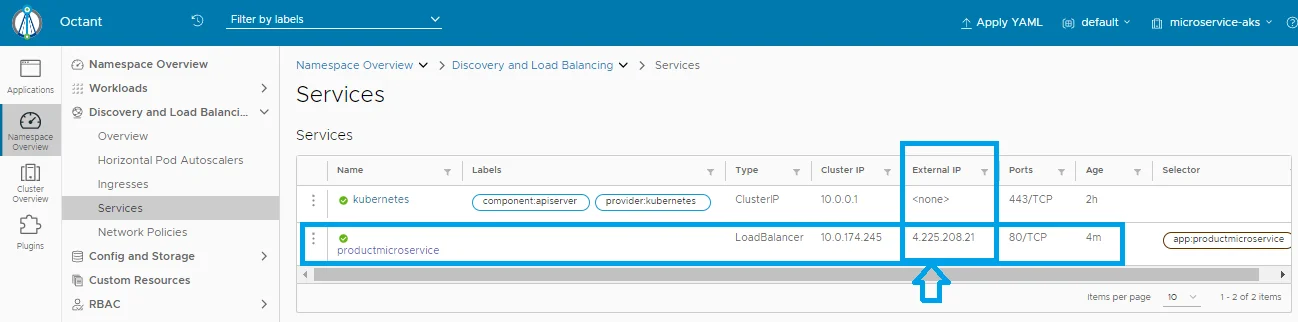
Service productmicroservice is created and has External IP: 4.225.208.21
Open browser with the external IP : 4.225.208.21, then the Swagger UI is displayed for ProductMicroservice as following:
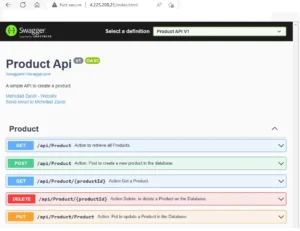
Swagger UI inj the productmicroservice: image pulled from ACR.
That is all.
We have created ACR, imported image from dockerhub, created AKS Service and configured, authorized to pull from ACR and tested it with KS8:dashboard.
In the end Cleanup all resources
When you are finished, delete all created resources in your Azure account. AKS creates three additional resource groups. Make sure to delete them too. Delete all resource groups.
Conclusion
In this post I have created an Azure Container Registry (ACR) in Azure Portal and Imported image from Dockerhub to ACR. Then I have created an Azure Kubernetes Service (AKS) and Authorized it to access to pull image from ACR. In the end I have tested it in KS8 dashboard (Helm octant), which shows the Swagger UI is uploaded from my application (ProductMicroservices).
All the Source code is on my GitHub.
Read about Alternative 2: Uploading Image to ACR from Azure DevOps Pipelines here.
About the author
Mehrdad is Consultant as System developer and Architect in Microsoft stack: .NET Platform, C#, , .NET Core, Micoroservices, Docker Containers, Azure, Kubernetes Service, DevOps , CI/CD, SQL Server, APIs, Websites, and more
In Frontend: HTML, JavaScript, CSS, jQuery, React, and more.
In addition I can build Websites by WordPress.
