
De “mjuka” argumenten för att bli frilanskonsult jämfört med att vara anställd konsult
De “mjuka” argumenten för att bli frilanskonsult jämfört med att vara anställd konsult
Jag heter Anna Leijon och jag har tidigare skrivit en artikel som jämför skillnaderna på pappret (de kontraktsmässiga skillnaderna) mellan att vara frilanskonsult och att vara anställd konsult. Här gör jag en övergripande sammanfattning av de mer mjuka faktorerna. De kontraktsmässiga är objektiva skillnader medan dessa är mer subjektiva och jag väljer att dela in dem i förutsättningar och sociala skillnader.
Min bakgrund är att jag är civilingenjör från KTH som arbetat både som anställd, anställd konsult och numer som egenföretagare och frilanskonsult. Det är ett av de bästa besluten som jag har fattat i mitt liv och därför vill jag sprida informationen och inspirera andra att våga ta klivet! Spana in min hemsida eller min Linkedin för att läsa mer från mig.
Förutsättningar:
Erfarenhet
○ Anställd konsult:
■ Både frilanskonsult och anställd konsult kräver en viss utbildningsbakgrund, men anställd konsult kan du bli direkt efter universitetet. Det är vedertaget att konsultbolagen tjänar mest på sina juniora konsulter och de jobbar hårt för att attrahera dem direkt från universitetet.
○ Frilanskonsult:
■ Det krävs oftast tidigare erfarenhet av heltidsarbete av liknande slag och jag har också stött på självlärda frilanskonsulter (utan högre utbildning) även om det är ovanligt.
Att hitta uppdrag
○ Anställd konsult:
■ Som anställd konsult säljs du via företagets säljteam. Säljteamet gör allting från att ringa så kallade “cold calls” till att säkra mångåriga ramavtal med företag som behöver konsulter.
○ Frilanskonsult:
■ Det blir enklare och enklare nu för tiden då fler och fler både konsultmäklare, konsultmarknadsplatser och olika tjänster har dykt upp. Det vanliga är att gå via konsultmäklare, såsom Developers Bay, men det är också möjligt att skaffa uppdrag via sina egna kontakter. Konsultmäklare tar oftast omkring 10 % kontinuerligt genom uppdraget. Jag har tidigare sammanfattat en fullständig lista över alla konsultmäklare och marknadsplatser i Stockholm.
Administration och bokföring
○ Anställd konsult:
■ Det är så gott som ingen administration eller bokföring som du behöver göra som anställd förutom att du möjligtvis behöver spara och redovisa kvitton och utlägg samt att alla arbetstagare behöver skicka in sin inkomstdeklaration själva.
○ Frilanskonsult:
■ När det kommer till administration och bokföring finns det också oerhört mycket hjälp att få, men jag gör allting själv sånär som på själva årsredovisningen. Det har dessutom dykt upp en uppsjö av bokföringshjälpmedel för egenföretagaren som underlättar enormt. De nya verktygen är så pass smarta att de säger till dig exakt när du behöver skicka in vad, men det är klart att du själv är fullständigt ansvarig i slutändan. Förutom att det tar tid så ser jag det också som en möjlighet med exempelvis skatteoptimering och du kan exempelvis roa dig med att försöka få ut pengarna ur bolaget på ett skatte-, ledighets- eller löneoptimerande sätt. Jag lägger ungefär kanske 45 minuter i månaden totalt utslaget på hela året på min bokföring och det är värt varenda sekund. Jag tycker dessutom att det är intressant
Startkapital i aktiebolag
○ Anställd konsult:
■ Ingenting.
○ Frilanskonsult:
■ Nyligen har regeringen sänkt startkapitalet till 25 000 kr för att starta ett aktiebolag, vilket jag tycker är superbra! När jag startade behövde jag ha 50 000 kr.
Sociala skillnader:
Säkerhet
○ Anställd konsult:
■ Det är många som hävdar att en anställning är tryggare än egenföretagande, men till exempel nu senast under Coronakrisen så var det fortfarande väldigt många som förlorade sina anställningar. Arbetsgivare är ofta företag som är vinstdrivande och de kommer självklart alltid att “se om sitt eget bo” först. Till syvende och sist är såklart den största tryggheten på arbetsmarknaden oavsett om du är anställd eller frilanskonsult alltid att ha attraktiv kompetens.
○ Frilanskonsult:
■ Frilanskonsultande är konjunkturkänsligt till viss del. Under Coronakrisen har jag pratat med frilanskonsultkollegor som vittnar om att deras uppdragsgivare försökt sänka deras ersättning, exempelvis. Vissa uppdragsgivare har försökt förhandla ett längre kontrakt mot en lägre ersättning och så vidare. Däremot ser jag det alltid som en möjlighet att gå tillbaka till en anställning eller helt förlita mig på min ekonomiska buffert i bolaget som jag har sparat ihop till. Det är desto svårare att gå från anställning till frilanskonsultande och på så vis finns det en inneboende trygghet för frilanskonsulter.
Det är helt enkelt så att du inte kan bli frilanskonsult om du inte kan bli anställd så du är redan attraktiv på arbetsmarknaden. Enbart genom att du har möjlighet att vara frilanskonsult bekräftar just det och det inger en trygghetskänsla i sig. Den ekonomiska bufferten är dock det viktigaste redskapet som jag har i min verktygslåda under lågkonjunkturer och på så vis har jag även fullständig kontroll och insyn i hur jag planerar för alla eventualiteter. Att du tjänar så pass mycket mer som frilanskonsult köper dig den trygghet du behöver, skulle jag vilja påstå. Motsvarande buffert är mycket dyrköpt som anställd. Det jag gillar mest med frilanskonsultandet är den fullständiga transparensen, att jag bara har mig själv att skylla och att jag vet exakt vad allting går till. Det är en oslagbar frihetskänsla!
Hemmahörande
○ Anställd konsult:
■ Jag har identifierat en trend, som jag dock tror är på nedåtgående framförallt i Corona-tider, men det är att arbetsgivare i allt större utsträckning försöker efterlikna vänskapskretsar. Ju starkare band mellan de anställda, desto svårare att sluta för den enskilda. Arbetsgivarna pratar om sin “starka, värdebaserade och unika kultur”. Arbetsgivaren spelar på folks känslor för du vill ju inte göra slut med dina vänner, eller hur?
Tidigare kände vi stark anknytning till exempelvis vårt grannskap på samma gata. Kan det vara så att arbetsgivaren är den nya knutpunkten nu när vi inte ens hälsar på våra grannar längre? En annan inlåsningseffekt är “sponsorskapet”, någonting som Sverige troligtvis har ärvt från den Amerikanska arbetsmarknaden. Mina kursare från KTH pratar om sina “sponsorer” på sina Amerikanska, men också svenska, arbetsplatser. Utan sin sponsor så finns det ingen som talar gott om en i “de viktiga sammanhangen”. Jag tycker att det är fruktansvärd setup som bara banar väg för “ass-licking”-kultur, falska löften och vassa armbågar. Den “hemmahörande”-känsla som många anställda känner tycker jag inte är riktigt sund eftersom den bidrar till en inlåsningseffekt som enbart arbetsgivaren drar nytta av.
Ju mer transparent arbetsmarknaden är och desto mindre inlåsningseffekter och trösklar, desto bättre för individen. Om dina kollegor verkligen är dina vänner så kommer du ju dessutom att behålla dem även om du eller de slutar (för annars är ni ju inte riktiga vänner). Som ni märker så värderar jag inte “hemmahörande” på en arbetsplats särskilt högt och om du gör det kanske inte frilanskonsult är ett bra upplägg för dig. Det du dock måste förstå är att alla teambuilding-aktiviteter, konferenser och liknande är pengar som du hade fått i egen ficka om du hade varit egen. Jag åker hellre med mina vänner eller familj på resa och bestämmer allting själv istället för att åka på konferens med en arbetsgivare, om jag fick välja. Arbetsgivaren är inte “schysst” som bjuder på konferens – det är pengar som de tar direkt från din lön.
○ Frilanskonsult:
■ Jag har dock aldrig känt mig så hemma som jag gör på mitt egna bolag, Roawr AB. Som frilanskonsult får jag en sund inställning till vad arbete faktiskt är – en transaktion – ett utbyte av pengar mot tjänster. Jag är upprörd över hur många mellanhänder som finns där ute och som försöker utnyttja det faktum att någon annan vill komma åt min kompetens. Ju mer friktionsfri transaktion desto bättre – för såväl mig som för uppdragsgivaren.
Långsiktig karriärbana och utveckling
○ Anställd konsult:
■ Som anställd får du coachning och du förväntas följa den löne- och karriärtrappa som så gott som alla IT-konsultbolag har satt upp. Om du vill avancera förväntas du inte bara börja coacha andra, utan även sälja andra konsulter och ta på dig personalansvar. Så småningom blir du partner (kanske efter 10 år) och då börjar du allt mer gå över till enbart sälj och/eller managing. Det finns ingen annan väg, skulle jag vilja påstå.
○ Frilanskonsult:
■ Många hävdar att de får utbildningar av sin arbetsgivare, men det kan du såklart köpa till dig själv i ditt egna bolag också. Det finns otroliga möjligheter med eget företag och med pengarna i företaget. Jag har exempelvis lärt mig ovärderliga företagsmässiga kunskaper, men också sparat ihop rejält med pengar i bolaget som köper såväl trygghet som frihet. Jag tog ledigt i 6 månader i somras med full lön och jag startar och leder egna initiativ på fritiden, så kallade egenprojekt, som exempelvis teamo.se. Jag hade varken haft pengarna, tiden eller företagsmässigheten för att starta och kunna driva sådana initiativ annars. Mitt långsiktiga mål är att sluta frilanskonsulta och gå över helt till att driva mina egna företag.
Samhälleligt ansvar
○ Anställd konsult:
■ Ingen kommentar.
○ Frilanskonsult:
■ Som frilanskonsult blir du tvungen att förstå och läsa på om hur allting fungerar. Jag känner mig genast mycket mer politiskt engagerad och hänger bättre med i debatter. Det är faktiskt fantastiskt intressant och lärorikt, för att inte säga roligt, att sätta sig in i bokförings-, skatte- och momsdjungeln och räkna på detta och diskutera med andra företagare.
Bemötande
○ Anställd konsult:
■ Generellt får du alltid viss annorlunda behandling som konsult och specifikt som frilanskonsult. Konsulter kan “ses lite ned på” i vissa kretsar och framförallt bland de anställda ibland på företag. Jag tror personligen att det grundar sig i ett slags avundsjuka.
○ Frilanskonsult:
■ Oftast är folk bara mer positiva och intresserade när du är frilanskonsult och egenföretagare jämfört med anställd konsult, enligt mina erfarenheter.
Här har jag som sagt försökt sammanfatta de “mjuka” skillnaderna mellan att vara frilanskonsult och anställd konsult. Läs gärna mer på min hemsida och hör av er till mig om ni har några frågor på pm@annaleijon.se
Lycka till i era karriärer oavsett vilken väg ni tar!

Anna Leijon
Frilansare och entreprenör
Vill du veta mer om oss på Developers Bay?

Time series classification – an overview
Time series classification (Fig. 1) is a relative late bloomer in the field of machine learning. However, in recent years there has been a real surge of data, algorithms and open source code that can be used to tackle problems in new and better ways.
This blog post aims to give a basic overview of the field. My aim is that it should be possible to follow for the interested reader even without a background in machine learning. Hopefully this will give you readers an overview and further avenues for explorations.
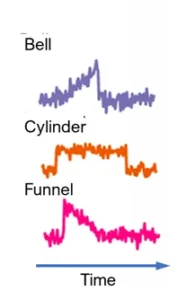
Fig. 1. Time series classification example. Samples from the widely used synthetic Cylinder-Bell-Funnel (CBF) benchmark dataset [1]. Each time series belongs to one of three classes: cylinders, bells and funnels. Adapted from [2] with permission from Patrick Schäfer.
Examples of time series and classification problems
A time series is just one (uni-dimensional) or several (multi-dimensional) temporally ordered sequences of numeric values. They are ubiquitous since anything numeric that you measure over time or in a sequence is a time series. For example:
- The temperature in Stockholm each day during 2020 (a uni-dimensional time series).
- Sales records
- Video (a multi-dimensional time series where each image corresponds to a time point. Note that here the data is also ordered in the pixel dimensions).
- Audio recordings.
- Internet-of-things and other sensor data.
- ECG/EEG and other medical signals.
- Transport data (e.g. when studying road congestion).
- The growth curve of a child (here the time points are not equally spaced, so this puts special demands on the algorithms).
Other types of data can also be viewed as/transformed into time series, such as written text, which is basically a time series but where the entities are not numeric. The beauty of this is that it lends the possibility to analyze time series using language models and to analyze language using time series models.
Time series classification problems are everywhere, so it is hard to know where to start, but the following are some random examples of making classifications from time series data:
- Classify of whom a voice recording is
- Classify an ECG as normal or give the type of abnormality.
- Surveillance: From a video, capture the path of an individual, then classify what he/she is doing.
- Internet-of-things: classify whether a kitchen device is malfunctioning.
- Speech recognition
- Classification of brain imaging or genetic expression data
You can imagine yourself that the applications of good algorithms are essentially without limit.
What is time series classification with machine learning?
In essence, time series classification is a type of supervised machine learning problem. Supervised problems have the following procedure: You get a set of time series, each with a class label. You typically divide the time series into three groups, the training data, the validation data and the test data. You train a number of algorithms/models on time series in the training data, observe which algorithm performs the best on the validation data and choose that one. Finally, you use the test data to determine the performance of the chosen algorithm.
The difference to many classification problems in machine learning is that the data is ordered along the time dimension, and as such a good algorithm would need to exploit this property of the data.
One should not confuse time series classification with forecasting. The purpose is different and hence the algorithms are, too. Forecasting aims to predict the next future values, and as such often relies more heavily on the end of a time series. It doesn’t need to compare different time series with each other. Rather it needs to find recurring patterns in data that are predictive of the (immediate) future. Classification on the other hand needs to find patterns in the data that are different between different classes in order to determine the class of the time series at hand.
So what are some of the algorithms used for time series classification?
Dynamic time warping, a benchmark algorithm
For at least a decade, a technique called dynamic time warping (DTW) combined with 1-nearest neighbor (1-NN) has been a benchmark for other time series classification algorithms to beat [3]. 1-nearest neighbor (Fig. 2) is a simple technique where you have a training set of time series [4]. You then classify a new incoming time series by finding the time series in the training data that is most similar, and assign the new time series to the same class as that one. You can also have k-nearest neighbors, where you find the k most similar time series and choose the most common class amongst those.
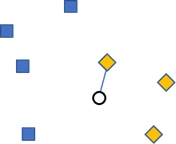
Fig. 2. 1-nearest neighbor. Based on a dataset of two classes (blue and yellow), a new datapoint (circle) is to be classified. By finding the nearest datapoint, the new datapoint can be classified as belonging to the yellow class.
DTW [5] is used to calculate the distance between two time series (Fig. 3); without a distance 1-NN cannot determine which time series is nearest. The most naive way would be to just take the distance between each point in the time series. However, it is not necessarily clear which points should be compared to which in the two time series. For instance, if two identical time series are just shifted slightly, then this would result in a big distance. DTW solves this by pairing up the different time points by drawing lines between them in such a way that each time point in a series must be connected to a time point in the other series, and two lines must never cross (Fig. 3). The distance is the sum of the difference between the paired time points. DTW chooses the grey lines in a way that minimizes this distance.

Fig 3. DTW. Points in two time series are connected in a way to minimize the distance between two time series (the combined length of all the grey lines). As can be seen from the gray lines being tilted, the latter half of the blue time series is shifted to the right of the latter part of the red time series. DTW is able to connect the corresponding points of the two series to calculate the minimum distance. Adapted from [6] with permission from Brian Iwana.
The benefits of a machine learning model
DTW+1-NN doesn’t build a machine learning model of what time series for a different class should look like. What I mean is, there is no model holding an internal representation of the world, no knowledge stored in any model weights. Instead it reaches its conclusions simply following a step-by-step procedure where it compares new time series to series in the training data. The benefit is that no model training is needed. But there are several drawbacks.
Firstly, classification takes a lot of time. For each new time series one must calculate the distance to all the time series in the training data. DTW is in itself an optimization problem, which means that the distance calculation is fairly slow, and for a big data set consisting of millions of data time series it must be repeated over and over again. Hence, it doesn’t scale beyond fairly small problems.
Secondly, a machine learning model is a way to capture our knowledge of data in a parsimonious way. For a real-life analogy, having a model is akin to having an expert at hand. The expert can just look at your new time series and say which class it belongs to. Training a human expert takes a long time, but once that is done, classification is fast. On the other hand, DTW+1-NN is like working with a non-expert given a recipe for how to go through the data and determine the class.
Having once captured your knowledge into a machine learning model means that you can employ this knowledge in many situations that are similar but not identical, a technique called transfer learning. For example, consider a model that has looked at many bird songs in order to separate between nightingales and canaries. In order to do so, it has had to learn many features of bird songs in general. If we now wanted to separate between a robin and a sparrow, we could use our previous model and just finetune it to hear the difference between these two species. This would be much easier than training a new model, because the old model has a good ear for bird songs in general already, so much less training data would be needed.
You might think that transfer learning would only be useful in obviously similar cases such as the above. Think again. Image classification has been a resounding success due to the availability of huge benchmark datasets of millions of images coupled with competitions that have driven the development of algorithms to beat previous records on those datasets [7, 8, 9]. Researchers have for some time now transformed one-dimensional time series into two-dimensional images using techniques such as gramian angular fields, and been able to classify these time series images successfully [10]. Think about how wild this is! The network has been studying photos of cars and airplanes and somehow learnt something useful for classifying bird songs. When I first heard that learning can transfer that far I was just blown away. The reason why this works is that there is some similarity on some level between the time series images and real images on which the network was first trained.
The above example is interesting from another aspect as well. We have a 2-D image model which is sub-optimal compared to a tailor-made 1-D time series model. However, since the image model has had much more training data, it performs better. It is the model-data combo that determines the performance, not the model in isolation.
Recent developments / Other approaches
Data availability
For time series, there exists a repository of datasets called UCR/UEA [1, 11] (from Univerisity of California, Riverside and University of East Anglia). It displays a wide variety of time series and all algorithms are benchmarked against it. In this way it is immensely useful in determining the relative performance of various algorithms. Compared to the corresponding benchmark repositories for images, text, etc, it suffers from being much smaller, having just on the order of 100 datasets, and with the biggest containing less than 10000 samples. For text, for example, you can download the whole of wikipedia very quickly. This comparative lack of data is hampering the development of the field. However, the repository is growing and being added upon every few years (most recently in 2018), which benefits research.
Perhaps due to relative lack of data, it has been difficult for new algorithms to beat DTW+1-NN, since more complex models would need more data to train all the parameters on. Below I describe some of the approaches that have performed better than DTW+1-NN.
Shapelets
One technique is to use shapelets [12]. A shapelet is a short time series that has been chosen because it is very indicative of a class (Fig. 4). For example, it could be a particular electrical pattern that is only emitted by microwave ovens and as such can be used when classifying home appliances. Shapelets are different from DTW because they focus on only parts of the time series. When you pass a time series through a shapelet algorithm the output is the minimum distance between the shapelet and all subsequences of the time series (this is called a shapelet transform). This data can then be used to train a classification algorithm, e.g. 1-NN or a machine learning model. In [13] an ensemble (see explanation below) of classifiers based on shapelet-transformed data was second best on the UCR/UEA dataset of all tested algorithms.
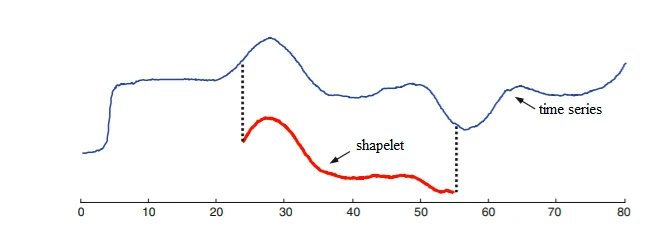
Fig. 4. Shapelets are small pieces of time series associated with a class. The distance between the time series (blue) and the shapelet (red) is the shortest distance between the shapelet and any part of the time series (here indicated by the dots). Taken from [14] with permission from Alexandra Amidon.
The main difficulty when using shapelets is that it can be hard to know which shapelets to use. One possibility is to manually craft a set of shapelets, but this can be quite difficult and time consuming. A better solution, if possible, is to automatically select shapelets. The way to do this best is an active field of research to a problem that is quite tricky due to the enormous amount of possible shapelets (see [15], section VI, and [13] for a good overview).
Another problem is really bad time complexity (how the execution time scales with the data): O(n2l4), where n is the number of training samples and l is the shapelet length [13]. This means that doubling the training data leads to a 4-fold slowdown and doubling the shapelet length leads to a 16-fold slowdown.
Model ensembles
Another approach has been to create model ensembles. “Collective of Transformation-Based Ensembles” (COTE) [16] from 2015 and its development HIVE-COTE from 2016 [17] are ensembles (collections, see below) consisting of many different models. COTE managed to increase the accuracy with 8% on the UCR/UEA datasets vs DTW+1-NN [13], which was the best of all algorithms tested. HIVE-COTE then significantly outperformed COTE and is the best algorithm to date that is not a neural network.
An ensemble is a collection of models each with its own classification, from which you pick the most common one. This works well if models have good enough accuracy and the errors that each model makes is different. For example, having three uncorrelated models with 90% accuracy each, for a given time series there is a 0.1*0.9*0.9 = 0.081 chance of one model giving the wrong answer, a 0.1*0.1*0.9 = 0.009 chance of two models giving the wrong answer and a 0.1*0.1*0.1 = 0.001 chance of three models giving the wrong answer. Taking the majority vote, the ensemble would give the wrong answer only in the latter two cases, representing 0.009 + 0.001 = 0.01 = 1%. Thus we have increased the accuracy of the ensemble to 99% vs the 90% of the single model.
An important factor for an ensemble is the degree to which the algorithms are uncorrelated (produce errors in different places). If all algorithms are totally correlated, they will produce the same results and so the ensemble will have the same accuracy as the individual algorithms. The authors of COTE noted that several of the 35 employed algorithms were minor variations of the same team (e.g. 50% worked in on auto-correlation and spectrum features). HIVE-COTE tried to address this by creating a hierarchy whereby all the algorithms were first grouped by type (DTW-based, dictionary-based, etc). Each major group first produced a joint classification and that was then entered into the ensemble classification. In this way they were able to avoid that the ensemble was dominated by one group of correlated algorithms, with the result of improved performance.
The biggest problem with COTE and HIVE-COTE is that several of the models rely on the shapelet transform and hence suffer from very bad time complexity, meaning that they take ages to run on a big dataset [13]. For this reason, the community has looked for faster alternatives. Another ensemble, TS-CHIEF, although not having higher accuracy than HIVE-COTE, is one such choice [18].
With so many models it is also very difficult to understand why the models classify the way they do. Interpretability is tremendously important. For example, it is not enough for a physician to say that you belong to the class of people for which there are little chances of survival in case of contracting corona virus and therefore we will not give you treatment.
Dictionary-based approaches
A third popular collection of techniques is called dictionary-based [13]. Basically, a dictionary is a list of words where you look up a word to retrieve something, e.g. an explanation of the word or the number of occurrences of the word in a text. So for instance one could classify a text as belonging to a type of field (e.g. sports vs law) by comparing the occurrences of different words.
But how does this apply to time series classification? Well, there are several ways to construct dictionaries for time series. One could use the shapelet approach above [12, 15] to count the number of times in a time series where there is a match between the shapelet and the time series. In such a dictionary the shapelet takes the place of the word and what you retrieve is the number of matches of the shapelet for the time series. An algorithm called ROCKET [19] is currently among the top-performing time series algorithms and does something similar. It has a large number of random kernels (very similar to shapelets) and they calculate for each kernel the percent matches. A simple classifier (logistic or ridge regression) is trained on the dictionary.
Another is the Bag-of-Patterns (BOP) algorithm [20]. It actually underperforms against DTW+1-NN [13], but I include it here because it illustrates the approach well. Like the Bag-of-Words algorithm used for text data, this algorithm counts the number of times a word occurs, only this time the words are created from numbers using a technique called Symbolic Aggregate approXimation (SAX) [21]. A bit oversimplified, you first split the time series into a number of larger time segments and normalize. Next you define intervals of the signal (y) value and assign a letter to each (e.g. A: <-0.3, B: -0.3 to 0.3, C: >0.3). You finally cut each segment into small pieces, calculate the mean for each piece and translate it to one of the letters (A, B, C in this case). In this way each segment consists of a string of letters, e.g. ABBC. You can then summarize the number of occurrences of each string into a dictionary, which can be used for classification.
Other dictionary approaches have been more successful, in particular an algorithm called BOSS [2]. It works similarly to BOP, but instead of translating the normalized original signal into words it works by Fourier transforming the signal into frequency space, low-pass filtering it and translating it into words using two algorithms called SFA and MCB. This has the effect of reducing noise. Furthermore, it creates an ensemble of different models that vary by the amount of low-pass filtering and the word length. In a comparison between many different algorithms on datasets from UCR/UEA, the BOSS algorithm was among the best, and is much faster on big datasets than COTE (complexity: O(n2l2)) [13].
One of the main reasons why dictionary based approaches work well is that the translation into words make them robust to noise.
Interval-based classification
The most typical interval-based algorithm would be the time series forest [22], a type of random forest. A forest is a collection of decision trees. Each decision tree is a machine learning model that takes a data point and assigns a class based on the value of its variables, as shown in Fig. 5. By creating a number of trees, each which gets to see a different part of the data, you end up with an ensemble of different tree classifiers (i.e. the forest), each possibly producing a different classification (since it has been trained on slightly different data). You then follow the usual ensemble procedure and choose the most common prediction as your final prediction.
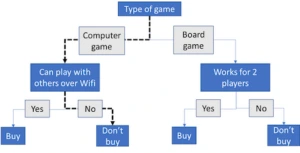
Fig. 5. Decision tree example. A decision tree takes a data point, in this case a game, which can be characterized along a number of different dimensions (here 3: a. type of game, b. multiplayer via Wifi, c. works for 2 players). By traversing the tree, we end up at a purchase decision (as illustrated by the dashed line, a computer game that does not allow for game play via Wifi will not be bought). In a random forest ensemble the aim is to produce trees with different structure whose errors are uncorrelated.
The special thing of a time series forest is that you divide your time series into n distinct intervals and for each interval you calculate the 3 values mean, standard deviation and slope [21]. Thus you end up with 3n variables that you input into the model. One of the tricks is to find how you split your time series into intervals. The performance of time series forests are not as good as BOSS or COTE [13].
Deep learning
Deep learning models are types of neural networks consisting of several, often many, layers of neurons (See [23] for a simple introduction). They typically contain many more parameters than other machine learning models. Often they consist of a “body” of layers to which data is fed. Whereas early layers represent basic shapes (e.g. a horizontal line in image models), the later layers encode semantically meaningful representations. Thus, the output layer of the body (the “neck”?) should contain what is meaningful and salient in the data. For example, in image classification the body can capture the presence of a car wheel and the neck all the information needed to discriminate between different makes, models and versions. On top of that is a “head” which is a classifier of some sort that makes a classification based on the output of the neck. By working on the neck rather than directly on the image, it is easier for the head to classify data into e.g. cars vs airplanes. In the last decade, deep learning models have become the obvious choice for classification of both images and language. For time series it has only recently gained in popularity somewhat, but still performance on the UCR/UEA datasets is as good as HIVE-COTE [3, 19, 24] despite being much faster.
Ways of training deep learning models
There are perhaps two different ways to train a deep learning model for time series classification (as is the case for many types of deep learning): unsupervised (generative) and supervised (discriminative) [23]. Supervised is what we talked about above. This is where you train the model to generate the correct classification. One problem with this approach is that the classes contain only little information (for a two-class problem only 1 bit of information), whereas the time series contains a lot more and the model has many parameters to be tuned. With generative learning one instead trains a model to output a whole time series. One approach is the auto-encoder, where one replaces the head with an inverted body. Since the neck contains a distillate of the information of the time series, by passing it through the inverted body one should be able to regenerate the original time series. Since the time series contains more information than the class, the network is trained to capture all the information in the neck that is needed to regenerate the time series well enough. Having performed basic training, one can then remove the inverted body and replace it with a head that you can then train on the classification task at hand. TimeNet is an example of this approach [25].
Model types
There are many different types of deep learning models. Since the field moves quickly in this area, I will not go into detail concerning the specific architectures. They are generally one-dimensional, and often are causal (meaning that a value only depends on historical values, not future ones). Previous models were often of a type called recurrent networks, but recently the most successful architectures have been so-called convolutional networks. Some of the architectures that perform at least as well as COTE are ResNet [3], Fully Convolutional Networks [3] (that can handle time series of different length), multi-scale convolutional neural networks [3] and InceptionTime [26].
Lack of data problem
Lack of data might be the main reason why training from scratch of deep learning models tailored specifically for time series data has not previously been able to beat the more traditional algorithms on the UCR/UEA datasets. This is suggested by the big discrepancy between time series and image dataset sizes [6] as well as the improvement of classification accuracy with deep learning model ResNet when synthetic data is added to the smallest datasets in UCR/UEA [27]. We end this section with some approaches to tackle the data problem.
ROCKET [19] is a model (not a typical neural network but with many similarities) that has taken the radical approach of randomly setting the weights of the model body without training. It chooses a large collection of different weights of various magnitudes in the hope that they will be able to capture a large variety of patterns in the data. This model has very similar performance to HIVE-COTE.
Another approach has been transfer learning. TimeNet [25] is created specifically to serve as a pretrained and publicly available time-series specific deep learning network for common use. There is also the transfer learning from image models mentioned above.
Finally, a third approach has been to increase the amount of data by producing artificial data. A good overview is given in two articles by Iwana and Uchida [6, 28]. This technique is called data augmentation and merits a blog post of itself, but one of the approaches has been to take two time series from the data belonging to the same class and mixing them. The secret of the sauce is how to do the mixing properly. As when calculating the distance between time series, one needs to find out which pairs of data points in two series are corresponding. So one approach has been to use DTW to pair up the time points of two different series and then take an average of the paired data points. Currently data augmentation is not an established practice in time series classification whereas it is in image classification [6, 28], but this is a field that will become much more important in the future. It will probably boost the performance of most algorithms, but especially more complex models such as deep learning models.
Last words
Above I have tried to give an outline to the enormous field of time series classification. For readers, whether you do or do not know machine learning, I hope that the above can guide you and set expectations should you start a time series classification project. One suggestion would be to find a dataset from UCR/UEA [1] that is similar to yours in order to get an idea of what could be achieved. If you know how to code and want to try out an algorithm, I suggest you download a dataset from UCR/UEA and try out a basic algorithm such as DTW+1-NN ([29] for a Python implementation) or one of the algorithms that perform well on a suitable UCR/UEA dataset. There are many algorithms out there, and many of the articles reviewed above come with source code from Papers with code [30]. Note however that the code is written by researchers and not professional developers, which means that the code might require some tweaking.
Working on a machine learning project is similar in many ways to working on a code development project. It is great to try things out on your own. Still, just like most code development work sooner or later needs developers, the same goes for machine learning projects.
References
- UEA & UCR Time Series Classification Repository. timeseriesclassification.com.
- Schäfer, P. (2015) The BOSS is concerned with time series classification in the presence of noise. Data Min Knowl Discov 29, 1505–1530.
- Wang Z. et al. (2017) Time Series Classification from Scratch with Deep Neural Networks: A Strong Baseline. IJCNN 2017: 1578-1585.
- Cover T.M., Hart P.E. (1967) Nearest neighbor pattern classification IEEE Trans Inf Theory 13(1)21–27.
- Müller M. (2007) Dynamic Time Warping In Information Retrieval for Music and Motion 69-84
- Iwana B. K., Uchida S. (2020) Time Series Data Augmentation for Neural Networks by Time Warping with a Discriminative Teacher. arXiv:2004.08780v1.
- Sultana F. et al (2018) Advancements in Image Classification using Convolutional Neural Network 4th Int Conf Res Comput Intell Commun Netw (ICRCICN), Kolkata, India, 122-129
- Krizhevsky A (2009) Learning Multiple Layers of Features from Tiny Images.
- Imagenet. www.image-net.org.
- Wang Z., Oates T. (2015) Imaging Time-Series to Improve Classification and Imputation. In: 24 Int Joint Conf Arti Intell.
- Dau H.A. et al (2019) The UCR Time Series Archive IEEE/CAA J Autom Sinica, (6) 6, 1293-1305
- Ye L., Keogh E. (2009) Time series shapelets: a new primitive for data mining. In KDD ’09: Proc 15th ACM SIGKDD Int Conf Knowl Discov Data Min.
- Bagnall, A. et al. (2016) The great time series classification bake off: a review and experimental evaluation of recent algorithmic advances. Extended Version. arXiv:1602.01711.
- Amidon A. (2020) A Brief Survey of Time Series Classification Algorithms Towardsdatascience.com.
- Gupta A. et al (2020) Approaches and Applications of Early Classification of Time Series: A Review arXiv:2005.02595v2.
- Bagnall A. et al. (2015) Time-Series Classification with COTE: The Collective of Transformation-Based Ensembles. In IEEE Trans Knowl Data Eng., 27, (9) 2522-2535.
- Lines J. et al. (2016) HIVE-COTE: The Hierarchical Vote Collective of Transformation-Based Ensembles for Time Series Classification. In IEEE 16th Int Conf Data Min (ICDM), 1041-1046.
- Shifaz A. (2020) TS-CHIEF: A Scalable and Accurate Forest Algorithm for Time Series Classification. Data Min Knowl Discov 34, 742-75.
- Dempster A., Petitjean F, Webb G.I. (2020) ROCKET: exceptionally fast and accurate time series classification using random convolutional kernels. Data Min Knowl Discov 34, 1454–1495.
- Lin J.et al (2007) Experiencing SAX: a novel symbolic representation of time series. Data Min and Knowl Discov, 15(2):107–144
- Lin J., R. Khade, and Y. Li. (2012) Rotation-invariant similarity in time series using bag-of-patterns representation. J Intell Inf Sys, 39(2):287–315
- Deng et al. (2013) A time series forest for classification and feature extraction. Inf Sci 239, 142-153.
- Kaggle Intro to Deep Learning.
- Fawaz H.I. et al (2019) Deep learning for time series classification: a review Data Min Knowl Disc 33, 917–963
- Malhotra P. et al. (2017) TimeNet: Pre-trained deep recurrent neural network for time series classification In: ESANN 2017 proc, Eur Symp Artif Neural Netw Comput Intell Mach Learn Bruges (Belgium).
- Fawaz H.I. (2020) InceptionTime: Finding AlexNet for time series classification Data Min Knowl Discov 34 1936–62
- Fawaz H.I. et al (2018) Data augmentation using synthetic data for time series classification with deep residual networks arXiv:1808.02455.
- Iwana B. K., Uchida S. (2020) An Empirical Survey of Data Augmentation for Time Series Classification with Neural Networks. arXiv:2007.15951v1
- Regan M. (2018) Github code repo: K-Nearest-Neighbors-with-Dynamic-Time-Warping
- Papers with code – time series classification

Fredrik Edin
Konsult Machine learning & data science
Vill du veta mer om oss på Developers Bay?

I learned React in 3 weeks and so can you!
Let’s start right away with the premise:
If you have few years of experience in software development, you can learn any programming language or framework in 3 weeks.
In 6 to 12 months no one will ever suspect that this is not your main language. Not your coworkers, not your manager, not even your own mother! Any language you pick today can be added as a skill to your LinkedIn profile 3 weeks from now!

Disclaimer
While the target audience for this article is mainly front-end developers with at least few years of experience, it is not really a technical one. Despite the abundance of software terminology and abbreviations, it is in fact a motivational one. I encourage you to read through it and skip the parts that make no sense to you. Happy reading!

For 10 years I’ve been doing Android almost exclusively. OOP was my religion. I had Clean Code under my pillow and a picture of Uncle Bob on my wall. Sure, I’ve switched from Java to Kotlin in 3 days, but Kotlin is pretty much the same, just fancier, synthetic sugar without calories. And sure, I’ve written some scripts to batch rename files or automate birthday wishing to my mom, but never Java Script, not even a single line. That would be blasphemy. Utter chaos. Never even did Right Click -> Inspect Element. The web is a black box to me. No hablo inglés.

In this article we’ll go through 5 specific steps that will make you an “expert” in the language you choose to learn. Expert of course has quotation marks, but it is also not an over statement. You will create a decent solution. It will look like is done by an expert. It will feel like is done by an expert. Why you may ask? Check this photo below:
Now, you don’t need to be an architect or an interior designer to understand that this is not a proper door placement, it is a disaster waiting to happen. Similarly, you don’t need to be an artist to appreciate a beautiful piece of art. Even if you don’t know details about light, shapes, color, composition and perspective, millions of years of evolution shaped our brains to appreciate the beauty of aesthetics. It is embedded in nature. It is universal.
So, if you ever wrote a piece of code that you thought it is beautiful in your primary language, you will write somewhat equally beautiful code in the language you will learn. Not just that, you will also be able to recognize beautiful code when you are googling stuff. You will be selective in your copy pasting.
Before we dive right into the 5 steps, let us first tell:
A short backstory
Few months ago I started my own company. As an entrepreneur, the most important decisions you will make is the choice between I will do this myself for a fraction of the cost and I will pay for a service. Few examples:
- Build your own website or use Wix
- Deploy your own backend or use Firebase
- Do your own paperwork or use Red Flag
- Create your own content or use GPT-3
While #1 and #2 are a matter of preference and largely depend on your existing skill set, #4 is a human’s denial that creativity is related to consciousness and there is no way that an algorithm can easily replace us, #3 is something absolutely no one wants to do!
Your idea is going to change the world and you cannot change the world if you are stuck filing in the receipt for the new PS5 console for your kids as a business purchase. You don’t want to learn the tax system, so you hire an accountant to deal with all that.

Soon, you discover that accountant also deal with expensive, clunky legacy systems that require a great deal of manual work. Pasting stuff in excel sheets, organizing folders on cloud storage, exporting reports in obscure formats. Naturally, you want to help with all of that, you want to provide a solution that will make life a bit easier for your accountant and find your first client in the process. Business is fun!
1. Find your motivation
The backstory leads us to step number one: Find your motivation. This is imperative for your learning process. Following basic tutorials or reading articles about best practices is a good place to start, but in order to truly progress, you need to get your hands dirty working on a real life problem, providing a real life solution.

So, go ahead and find your motivation. Your pet project that needs a revamp, that app your cousin insists is going to be the next unicorn, a simple tool to connect with your grandma that features two big emojis and a parallax header of you being little and eating her meals, a beautiful app featuring a map and a gallery of misplaced electric scooters,… Anything works.
Not motivated by random examples? Just ask a person you interact with about a problem they have and try to solve it with software. Make someone redundant. Have fun.
Still nothing? There is an app for that! You can even build an app idea generator yourself.
Bonus step: Find your time
Motivation is nice and all, however you do need to find time to express yourself creatively. If your partner or child is screaming for attention while you navigate tight deadlines, maybe learning a new language will add fuel to the fire. But on the other hand, you get ahead in life by over promising and hopefully over delivering, so feel free to skip this step, who needs time!
2. Understand your motivation
Congratulations, you found your motivation and have a nice thing you can build. Now go ahead and light a scented candle, play some relaxing music, assume a meditative posture and look deep inside yourself to understand why are you doing this.

Few common reasons:
- You are bored during the pandemics
- You feel like you are lagging behind with your skillet and feel a need to stay relevant
- You are helping out a family member, a friend or an associate
- You secretly hope that this will scale one day, you will become ultra rich and beat the CEOs of tech companies in their quest to colonize the solar system
- You accept the reality that no human will ever need to code 10-ish years from now and you want to enjoy it while it lasts
Understanding the reason behind your willingness to learn a new language or a framework will help you tremendously in making the right decisions. It will do this by revealing the constraints.
For example, to solve the problem my accountant was facing we needed to make a solution that is:
- free or extremely cheap – we try to optimize, not introduce more cost
- multi platform – mobile apps and a web admin tool
- complete – you are trying to solve a problem after all
- doable within a month or two – your time is precious
- not terrible – functional and stable, but not too fancy
And this is how I learned React. Found a reason to build something, understood what needs to be done and chose a framework that covers most of the ground. With little difference between React Native and React JS you can cover the mobile apps and the web admin tool by learning a single language (JavaScript) and single framework (React). You can even take it up a notch and reuse some of the code, but let’s not get ahead of ourselves.
Bonus step: Doubt your understanding
Why React and not Flutter? You can pretty much build web applications with Flutter as well, plus Dart is much closer to Java your old friend than JavaScript. Oh, I just got reminded how much I miss Kotlin. Synthetic sugar overload. So slick. How is Kotlin Multiplatform coming along? What about Ktor? Too many options to choose from. Information overload. We are providing a solution, not waging tech holy wars. Skip this step, React is just fine.
3. Start from the top
Contrary to the popular belief, masterfully expressed in one of the Drake’s songs,

you really don’t need to start from the bottom. You don’t need to understand the basics of JS syntax, the difference between undefined and null or flexbox magic. You don’t even need to dread the lack type safety and consider Type Script. None of that. You only need to add the current year to your web searches. For example: “How to build a React Native App 2020” or “Free web admin templates React 2020” and start from there.
React introduced hooks in 16.8 so goodbye classes! You will never ever have to learn that part of history, unless for some reason you decide to work on legacy code. What about state management? Redux seems like a super boilerplate-y answer to your needs. Add 2020 to that search and you’ll discover a toolkit. Start from there. What about Recoil. Maybe none of that. Hooks will do the job.
What about UI that looks consistent on all platforms? Check out Material or Paper, all apps and all web pages look alike nowadays, no need to reinvent the wheel. Everything that you want to achieve is already done, you just need to put it together. Oh wait, Adobe made Spectrum. By the time this article gets published 20 more frameworks will pop out. It is obsolete already.
Anyways, start from the top and google your way down. It is impossible to understand every single concept you will encounter, every underlying mechanism or language sugar. It is also unnecessary, you have your mission, just search for the thing you are trying to figure out, add the current year to the query and read away.
Bonus step: Go strict
Establish a strict policy. Consider lint warnings as errors. Make your code pretty. Add style hooks to your commits. If you are starting from zero might as well go all in. In the next 3 weeks you will practice expressing yourself in a different manner, it only makes sense to try to express yourself flawlessly. Or it doesn’t. Beauty is in the eye of the beholder. Skip this step, it introduces too much friction.
4. Connect with your inner child
You know who is especially good at learning? Kids. They are awesome at learning. No wonder half of the spiritual advice you can get nowadays is to connect with your inner child if you want to grow and experience the world in a more profound way.
Kids don’t understand the rules of football. They have no idea what offside is. They have a ball and a goal and they kick the ball in the general direction of the goal. Over time they learn all known tricks that increase the likelihood of having the ball in the goal and over even more time they introduce new, previously unheard of tricks that get them ahead in the game.

This is the best way to approach this. Not just this, anything new you want to learn in life. You don’t need to understand everything or discover all the tricks, you just need to aim for the goal and commit to kicking the ball towards it. A little bit closer every day.
Connect with your inner child. Explore your curiosity. Ask questions, but don’t stop when you don’t get a proper answer. Be undefined. Choose what value you want to assign yourself as you go. Don’t let a static compiler check to determine who you are. Play. Have fun. Make bold claims and amend them the next day. By the time you are close to a shooting distance, you can scissor kick the ball, publish your app, update your LinkedIn profile with the new skill and write a blog post explaining how you shot for the stars and landed on the moon.
Bonus step: Scrape everything and start over
OK, don’t do that just yet. Scrape everything and start over. Your code is bad. It will never scale. Your view layer is tangled with your business logic. You don’t even downscale the images you upload to your storage and will soon reach the quota limits of your free plan. People will hate it. There are much better solutions out there. You were right from the start to doubt yourself. Again with the overthinking. Is this a part of the normal development process? Silence the internal critic and skip this step as well, you made something awesome!
5. Go public
You have to. Going public is the best way yo make a commitment. You don’t have to publish the app on the App Store or Google Play and go through cumbersome submission processes, but go public somehow. Send an email to your friends asking for feedback, write a semi-humorous blog post to justify your efforts, push your code to GitHub, answer a question on Stack Overflow with your new gained expertise, make a PR on the library you used, motivate your surrounding to learn something new as well,…

Get creative, contribute somehow to the big data, make it easier for the algorithms to understand how humans learn, they may suggest improvements in the future based on your experience.
You may feel a strong urge not to go public, especially if you did not manage to produce something tangible in these 3 weeks. But, before you go ahead and associate work with measurable output, ask yourself these two questions:
- What did you learn?
- Did you have fun?
If you learned something you did not know before and you had fun doing it, than you’ve successfully completed this tutorial and you’ve proven yourself that what sounds improbable is in fact quite possible. You are awesome, give yourself some love
A short summary
That’s all. Well, probably there is lot more to it, but this is the level of insight you can expect from a random blog post on the Internet about learning something that differs only slightly from what you already know. Not a lot of new information, nothing too profound or insightful.
Just a gentle reminder that you are not defined by your past choices. You are not limited by your existing knowledge. You are not stuck with a technology. You are free. You can learn pretty much anything at any time and have an amazing time doing it.
So, go ahead and do it!
Medo is an entrepreneur with extensive experience in software development and team leadership. He engages in projects ranging from hacked together proof of concepts to distributed solutions serving millions of users.
Medo loves sharing, he believes it is the optimal way of learning. He often speaks at events and social media on topics varying from technical solutions to inspirational talks. His enthusiasm for exchanging knowledge goes from vegan food recipes and body hacks, to quantum physics and the origin of the Universe.
At the moment, he is pursuing a dream to create a better workplace for everyone, helping individuals and organizations embrace a more mindful and heart based approach to leadership. He would love if you connect with him on LinkedIn.

Ivan Dimoski
Android expert & Mindful leader

Elixir och en framtid med större möjligheter
Elixir är ett programmeringsspråk som vunnit mycket mark på senare tid och i min erfarenhet vinner ovanligt mycket mark bland mer erfarna, seniora, utvecklare. Jag vill belysa lite av de systematiska fördelar jag ser Elixir ge företag och utvecklare. Det blir ingen kod, bara översikt och förklaring i det här läget. För att kunna bekanta oss med Elixir och dess fördelar behövs en liten historielektion som ger oss Elixirs tekniska arv och sammanhang.
Elixir bygger på arbetet med ett annat språk som heter Erlang. Det är ett språk som utvecklades på Ericsson på 80-talet och därefter släpptes som open source. Det skapades för att bygga system med fokus på driftssäkerhet, tillförlitlighet. Mer specifikt byggdes det för att ge mjuka realtidsgarantier för distribuerade system inom telekomsystemen som Ericsson skapade. Erlang har ovanliga egenskaper som man inte ser i särskilt många andra språk. Särskilt inte samlade:
- Hot code reloading: Man kan uppdatera koden i en körande applikation och bibehålla existerande tillstånd, utan omstart.
- Stark introspektion under pågående körning.
- Mjuk realtid, tillförlitliga latency, preemptive scheduling: Under körning kan VM:en avbryta pågående arbete för att säkerställa att alla pågående processer får chans att köras på CPU:n. Detta hindrar flera patologiska feltillstånd, t.ex. oändliga loopar, från att krascha eller låsa applikationen.
- Distribution & klustring: Erlang har en inbyggd lösning för distribuerad körning och klustring som bygger på message passing. Detta grundar sig på att Erlang är byggt enligt Actor-modellen.
- Concurrency & Parallellism (använda flera kärnor) Väldigt få språk kan effektivt använda CPU-kärnor hejvilt men i Erlangs fall så hanteras det med samma modell som utvecklades för distribution. Lättviktiga “processer” istället för trådar. Immutability och message passing för tråd-säkerhet. Så det är billigt och tämligen ofarligt att nyttja flera kärnor i en applikation, utan att använda en worker-pool i någon slags applikations-server eller köra fler instanser av applikationen.
Erlang har aldrig varit särskilt populärt men har länge respekterats i sin niche. För vissa företag har det varit ett hemligt vapen. Det är skapt för att kunna bygga extremt tillförlitliga system med goda prestandagarantier och det har såvitt jag vet alltid levererat väl på det området. Det har förstås också utvecklats löpande sedan 80-talet. Och det har körts i seriösa driftsammanhang sedan dess.
Elixir ger Erlang en fräsch och enklare syntax. Det lägger vidare till en hel del smidigare funktionalitet för modern utveckling och har blivit en renässans för Erlang och BEAM:en, den VM som Erlang och Elixir körs på.
Så varför bör vi bry oss om Elixir?
Grundplåten
Antalet språk som har ett gott rykte som exceptionellt pålitliga är få. De är också ofta trögarbetade. Elixir är ett tight och uttrycksfullt högnivåspråk som har mycket av sitt syntaktiska arv från Ruby. Elixir är dock funktionell programmering, inte objekt-orienterat. Precis som Erlang.
Webbramverket Phoenix, Ruby on Rails andliga efterträdare
Elixir skapades av José Valim som tidigare varit en aktiv Ruby-utvecklare. Rails är ett extremt populärt webbramverk. För Elixir är Phoenix det motsvarande ramverket och en stor mängd utvecklare från Ruby och Rails har rört sig över till Elixir och Phoenix.
Det går att skriva mycket om Phoenix, det är ett kraftfullt och lättarbetat webbramverk. Utifrån det så har även en del mycket imponerande tekniska lösningar byggts. En intressant utveckling är t.ex. tillägget LiveView som låter utvecklare skapa mycket dynamiska lösningar utan Javascript. Den här videon från Chris McCord kan vara en bra dragning.
Ekosystemet
Språket har ett starkt växande ekosystem och de mjukvarubibliotek som behövs finns i allmänhet i mogna implementationer. Det har även fördelen av att kunna luta sig på och använda bibliotek som skapats för Erlang när Elixir-varianter helt saknas. T.ex. bygger Phoenix på en HTTP-server som heter Cowboy som utvecklades för Erlang.
IoT & Connected Devices
Inom Elixir har ett projekt som heter Nerves skapats som har ett exceptionellt ambitiöst och synnerligen kapabelt sätt att närma sig arbete med hårdvara för IoT och liknande embedded-projekt. Om det kan köra Linux så kan det tjäna på Nerves. Det är en verktygskedja med exceptionellt snabb iterationshastighet för hårdvarunära utveckling. Det nyttjar en kombination av gedigen erfarenhet av hårdvaruutveckling och Erlangs egenskaper för att skapa pålitliga hårdvaruenheter. Det har även skapats ett verktyg vid namn NervesHub som löser säkra uppdateringar av produkter som är ute hos kunder i fältet vilket kan vara väldigt komplext. Det går att läsa mer här.
Ett annat ramverk som gör nytta inom IoT och Connected Devices är Scenic. Detta är ett UI-ramverk som använder OpenGL för att rendera lättviktiga UI med ett starkt säkerhetstänk och god flexibilitet. Scenic är enormt lättviktigt jämfört med den populära lösningen att bädda med en hel webbläsare och webbapplikation. Det är få system som har egna lågnivå-ramverk för att rendera användargränssnitt och Scenic är en imponerande lösning för det. Här presenteras det på ett talk på Code BEAM i Stockholm.
Varför Elixir?
Så varför bör vi överväga Elixir?
Med en stark modell för concurrency och parallellism drar det bättre nytta av serversresurser än genomsnittliga applikationer skapta i t.ex. Python, Node.js, Ruby, PHP och många fler. Detta sparar pengar, ofta rejäla pengar, på hårdvara eller notan hos molnleverantören.
Det är en stark grund att stå på. Elixir och Erlang erbjuder verktyg som i princip inga andra språk eller ramverk rimligt kan erbjuda när det gäller slagtålighet i drift, distribution och skalbarhet,
Funktionell programmering är enligt många avsevärt enklare att resonera kring. Min erfarenhet som konsult som klivit in i andra organisationers Elixir-projekt är att jag är feature-produktiv dag ett eller två och blir bekant med systemet snabbare. Vare sig jag återbesöker kod jag skrev för 6 månader sedan, dyker ner i koden i ett open source-bibliotek så är den lättare att plocka upp då jag inte behöver hålla en klass-hierarki och objekt-state i huvudet när jag läser och skriver kod. Input, output och minimalt med bieffekter.
Den största utmaningen är väl just att funktionell programmering är ett annat paradigm än objekt-orienterat och att objekt-orienterat fortfarande är dominant. Men sen har ju många ekosystem, särskilt Node.js/Javascript plockat upp funktionella koncept så det är mer och mer bekant för utvecklare.
Man kan bygga webbsystem och backends i nästan vilket språk som helst och få det att fungera fint. Det är min bestämda uppfattning att Erlangs VM, BEAM, erbjuder egenskaper som man inte hittar i något annat moget ekosystem eller språk. Och att de egenskaperna är enormt användbara för majoriteten av backendsystem som byggs idag. Elixir är nyckeln till att göra Erlang lika enkelt som andra moderna språk. Och därav ser jag att Elixir, till sin största fördel, höjer taket för hur bra ett system kan byggas.
Mail: lars@underjord.io
Webisite: underjord.io
Twitter: @lawik

Lars Wikman
Rådgivare & problemlösare

Vi behöver inga fler snygga kundresor, vi behöver organisationer som tar ansvar för sina kunder!
Design har äntligen hamnat i fokus hos ledningsgrupper de senaste åren. Företag som Google, Apple och Facebook har påvisat att genom att fokusera på design går det att bli framgångsrik. I takt med att allt flera organisationer börjar prata om design börjar även olika verktyg och metoder dyka upp inom området. Ett myller av begrepp och termer som gör att även jag som jobbat 20 år med design, har svårt att förklara likheter och skillnader mellan de olika definitionerna.
Fokus på kundnytta
Design thinking, kundresor, design sprints, Lean UX, Customer Experience, User Experience, Service Design, tjänstedesign m fl. är begrepp, metoder och verktyg som egentligen består av samma sak, designprocessen. En process som hjälper organisationer att skapa framgångsrika företag med fokus på kundnytta. Där design innebär utformning och utseende av en produkt, och är den skapande process som används från idé till färdig produkt.
Designprocessen är en viktig del i den digitala transformationen
Designprocessen finns på olika nivåer i organisationen men alla har samma utgångspunkt, att förstå kunderna på djupet, för att sedan kunna leverera kundnytta, kundlojalitet och engagemang. Att implementera designprocessen på olika nivåer i en organisation är en viktig del i den digitala transformationen. Idag anlitas konsulter för att på en strategisk nivå ta fram kundresor. Ett fantastiskt verktyg som genom user research (inte internt tyckande) kartlägger kundernas kontaktytor och interaktion med företaget. Resan utgår ifrån målgrupperna, deras behov och beteende och organiseras därefter: utifrån och in istället för inifrån och ut.
Kundresor som process med mätbar användarnytta
Kundresor blir tyvärr allt för ofta fina presentationer som inte bidrar till kundnyttan. Presentationerna blir liggande i en byrålåda eller som hyllvärmare, eftersom organisationen inte har förmåga att exekvera på förändringar och förbättringarna som identifierats i kundresorna. Det finns även en förställning kring att kundresor är färdiga dokument, men istället skulle jag vilja se det som ett verktyg som ska uppdateras och ändras varefter fler insikter görs om kunderna. Arbetet med nya och fler insikter är en ständigt pågående process som ska genomsyra hela organisationen.
Vi behöver inga flera snygga kundresor. Vi behöver organisationer och ledningsgrupper som tar ansvar för sina kunder, och möjliggör att företaget organiseras för att stötta designprocessen med att arbeta kunddrivet. Organisationer ska möjliggöra att det finns tid att förstå och utveckla sina kundrelationer samt att alla i organisationen får ökad kunskap om kunderna. Företaget utvecklar ständigt nya kontaktytor utifrån hur kund- och användarbeteende förändras. De företag som är, och kommer att bli konkurrenskraftiga, är de som snabbt kan ställa om för att möta förändringar i kundbeteende eller lösa nya problem. Faktum är att varje gång kunderna kommer i kontakt med företaget, testas dess förmåga att förstå och möta kundens behov. Förutom tydliga designprocesser behövs tydlig vision, strategier och mål. Få organisationer idag har KPIer för att mäta användarnytta. Hur vet man då att man lyckats med sina investeringar? Allt för ofta överskuggas användarnyttan av affärs-KPIer och det är därav det som får fokus.
5 komponenter för att arbeta med designprocessen och skapa kundnytta i din organisation:
Organisationsstruktur
Företaget måste organisera sig på ett sätt som underlättar att arbeta med kundnytta. Detta innefattar både tydligt styrning och ledning, tydliga KPIer för kundnytta, möjliggöra samarbeten mellan avdelningarna och definiera processer för att samla och sprida kunskap om kunderna.
Tekniska möjligheter
För att kunna leverera nya digitala tjänster till kunderna behövs en snabb stabil infrastruktur. Rent konkret innebär detta möjlighet att lansera tjänster dagligen, för att sedan mäta och förädla.
Lyssna på dina medarbetare
Lyssna på företagets säljare, teknisk support, kundtjänst etc. som dagligen har kontakt med era kunder.
Lyssna på dina kunder
Analysera hur kunderna beter sig på webben eller i era appar. Gör beteendeanalyser genom djupintervjuer. Förstå vilka problem kunderna vill lösa, förstå deras värderingar och beteendemönster. Ta reda på vad kunden vill ha. Varför de misslyckas med sina köpflöden? Varför köper dom samma tjänst från konkurrenterna etc.
Arbeta strategiskt och operativt med kundnytta
Möjliggör att verksamheten har utrymme att arbeta strategiskt och operativt med designprocessen. Få organisationer har hittat balansen mellan dessa två. En del organisationer arbetar för operativt och det finns inte tid att göra det långsiktiga arbetet. Ex. vilka nya målgrupper eller beteendeförändringar måste vi ta hänsyn till om ett år? Andra organisationer jobbar för strategiskt och då blir ofta resultatet dokument, men det tänkta resultatet av strategier levereras aldrig till kund.
Designprocesser är inget nytt. Pyramiderna i Egypten, kinesiska muren och Leonard da Vincis uppfinningar konstruerades precis enligt samma principer. Men det som saknas idag i allt för många företag och organisationer att ta ansvar för att arbeta utifrån kundperspektivet. Det är dags att sätta kunden i fokus och på riktigt ta ansvar för sina kunder.
Kommentera och dela gärna om du gillar detta inlägg. Hur arbetar ni med kundresor och designprocesser hos er? Dela gärna med dig, vi är alla nyfikna! Hör gärna av dig om du vill diskutera vidare. Anette Lovas, konsult inom digital produktutveckling, förändringsledning, UX/CX
Denna och fler artiklar hittar du här.

Anette Lovas
Konsult UX & Webb

Introduktion till Flutter för utvecklare
Varje gång ett nytt ramverk, programmeringsspråk eller verktyg presenteras så blir vi lovade att detta kommer lösa alla problem som de tidigare alternativen misslyckades att hantera. Flutter, Googles cross-platform lösning för appar, är egentligen inte annorlunda ur den aspekten. Det som talar för Flutter handlar mer om att Google undvikit de misstag som andra cross-platform lösningar gjorde, och på så vis har de skapat något som jag tror kommer ta över en stor del av app-utvecklingen framöver.
Oavsett om jobbar med backend, frontend, eller apputveckling, så är Flutter en teknologi som du borde känna till och förstå. Det som gör Flutter populärt är sådant jag är övertygad om kommer ha en inverkan på andra tekniker. Genom att förstå Flutter så blir du alltså bättre förberedd på hur både appar och webb kommer att byggas framöver.
Deklarativt UI
På senare år så har konceptet declarative programming dykt upp som ett populärt alternativ till det mer traditionella imperative programming. Jag kommer inte göra någon djupdykning i skillnaderna mellan dessa, utan istället fokusera på hur deklarativ programmering fungerar i Flutter. Min förhoppning är att min genomgång och exempel här ska få en bild om varför det är en stor fördel framför andra modeller, och varför Flutter också är ett bättre alternativ än andra deklarativa ramverk (sett till vad vi har för alternativ idag).
Flutter deklarativa modell för att bygga användargränssnitt bygger på Dart, det programmeringsspråk som Flutter använder. Genom en smart design av hur koncept som optional parameters och default values fungerar så har man kunnat skapa en modell för att beskriva användargränssnitt på ett konkret och lättläst vis. Andra ramverk, som React, har också en deklarativ modell, men där har man fått kompromissa med underliggande tekniker och befintliga standarder på ett sätt som skapar en mindre optimal modell för att bygga gränssnitt. Följande kod är ett exempel på hur man bygger en enkel widget i Flutter:

Ovanstående visar på hur Flutters deklarativa modell uppnås genom språket Dart. Ett antal olika widgets kombineras i ett träd för att komponera vår nya widget. Detta görs genom att i funktionen build() konstruera vårt träd. Column representerar helt enkelt en kolumn med flera andra widgets under sig. Vi skapar denna genom att anropa konstruktorn och skicka med två parameterar, mainAxisAlignemnt och children. Den första, mainAxisAlignment, är en valfri parameter och om den inte anges så får den värdet start, vilket medför att dess barn positioneras från toppen och nedåt. Den här modellen att ha valfria parametrar med standard-värden gör att man oftast bara behöver ange ett fåtal när man använder en befintlig widget, vilket i sin tur förenklar koden man behöver skriva.
I Flutter är widgets inte bara komponenter som är synliga, utan också komponenter som lägger till utfyllnad (padding) eller som asynkront laddar data och bygger om din widget när den är klar. Följande exempel visar hur widgeten FutureBuilder kan användas för att ladda data asynkront och visa en ikon (med en smiley) innan den är klar, för att sen bytas ut mot en Text med användarnamnet.
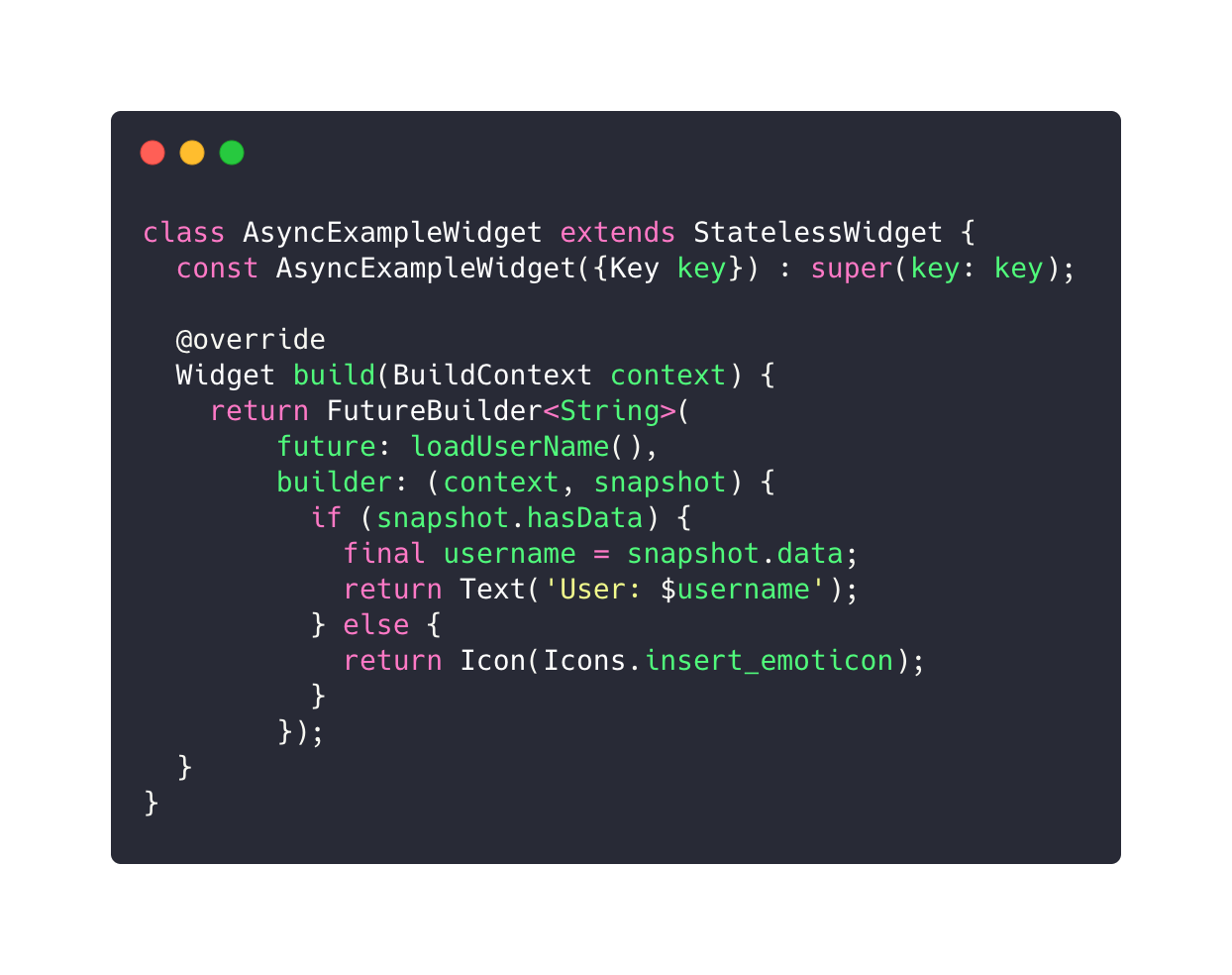
Observera att en widget alltså kan välja att rita om delar av sig själv och behöver inte ens returnera ett träd med samma typ av widgets när det sker. Det här gör det alltså möjligt att beskriva vårt användargränssnitt baserat på olika villkor, och fortfarande använda en deklarativ modell.
Developer Experience
Ett begrepp som har börjat användas mer på senare år är Developer Experience. Detta används för att beskriva hur användningen av ett utvecklingsverktyg, programmeringsspråk eller ramverk upplevs av utvecklare. En bra Developer Experience är alltså något som utvecklare uppskattar och upplever vara mer effektivt att arbeta med. Huruvida en teknik är bättre eller ej handlar ju ofta om subjektiva uppfattningar, vilket är anledningen till att en god Developer Experience är en viktig komponent när man ska välja teknik. Är verktygen undermåliga, programmeringsspråket föråldrat, eller ramverket komplicerat att använda så är risken stor att det kommer medföra att utvecklarna blir mindre effektiva.
Flutter har ett utmärkt stöd i den mest populära texteditorn på marknaden idag: Visual Studio Code. Det finns även tillägg till IntelliJ IDEA från JetBrains om man föredrar det verktyget. Bra stöd är viktigt, men för att bli riktigt framgångsrikt så måste verktygen också vara smarta. Flutter-stödet i Visual Studio Code (och IntelliJ IDEA) har flera viktiga funktioner för att snabbt kunna redigera koden för ett UI. I exemplet nedan visas hur man snabbt och enkelt kan modifiera sitt widget-träd med hjälp av enkla snabbkommandon.
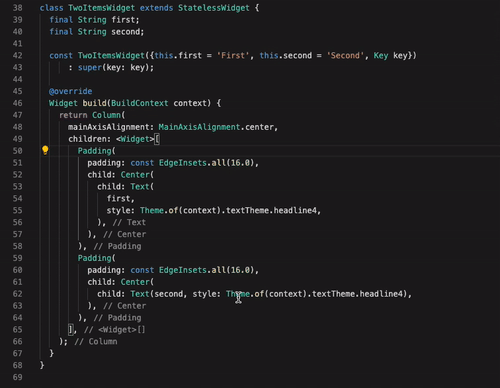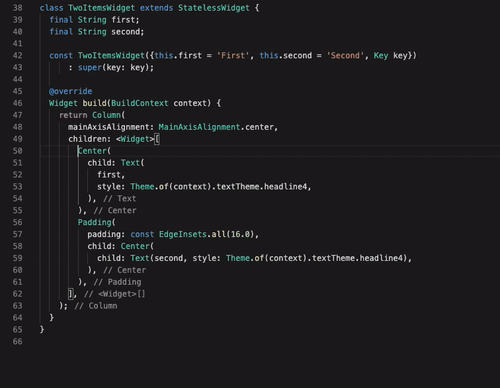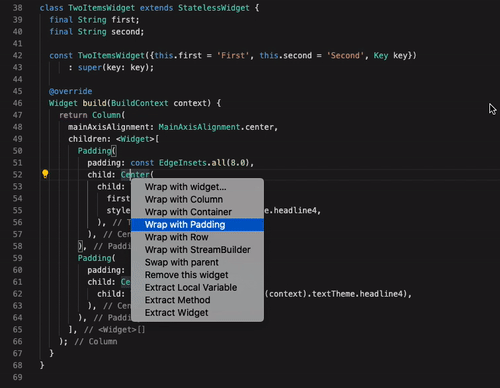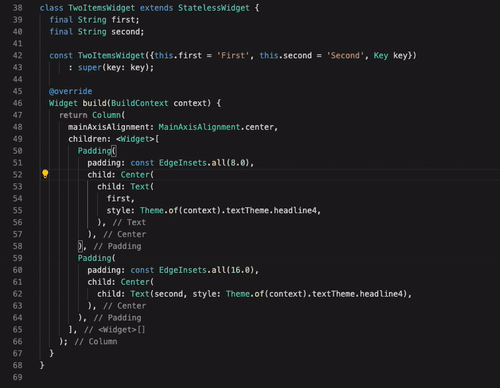
Denna funktion blir extra viktig när man använder en annan funktion i Flutter: Hot Reload. Detta låter en utvecklare uppdatera en app som körs på en telefon eller emulator, utan att behöva starta om den helt. Det går alltså att i realtid se hur ditt UI påverkas bara genom att du sparar koden i texteditorn efter en ändring.
Smarta funktioner ger en bättre upplevelse för utvecklarna. Detta gör dem i sin tur mer effektiva när de arbetar med den tekniken, vilket reducerar tiden det krävs för att bygga klart appen. Developer Experience är en viktig komponent, och Flutter är idag bäst i klassen.
Fokus på prestanda
Ett vanligt problem med cross-platform lösningar är att de måste kompromissa på områden som gör att slutanvändaren kan bli lidande. Ett vanligt problem är att prestandan i användargränssnitten blir avsevärt mycket långsammare än om de skrivits med den native teknik som respektive operativsystem erbjuder.
Flutter har från början lagt ribban för prestanda riktigt högt. Motorn i Flutter garanterar minst 60 FPS (120 FPS om hårdvaran tillåter det), och det är svårt för en utvecklare att av misstag strypa den hastigheten. Detta gör att användarupplevelsen i en app byggt med Flutter känns rapp och responsiv utan att användaren behöver lägga särskilt stort fokus på det området.
Prestandan i Flutter handlar inte bara om hur många FPS den kan rita ut i, men också om att den kan bygga om ett stort och relativt komplext träd av widgets mellan två frames. Det är alltså inget större problem att ditt UI helt ändrar struktur och bygger om alla widgets, då motorn i Flutter är optimerad för att göra just detta. Det här gör att koden för en Flutter app blir enklare och lättare att återanvända. Man behöver inte längre bygga avancerade komponenter som klarar många olika utseenden. Istället bygger man widgets som är specialiserade och växlar snabbt mellan dem vid behov.
Fokus på användargränssnitt
Även om appar har ett stort fokus på användargränssnitt så finns det många situationer när man vill att en app ska köras i bakgrunden. Vanliga exempel är musikspelare eller träningsappar, som vi vill ska fortsätta att köra även om de inte ligger i förgrunden eller när skärmen är släckt. Detta är också exempel på de typer av appar där Flutter passar mindre bra.
Eftersom Flutter har fokuserat helt på att skapa ett ramverk för att bygga användargränssnitt, så har möjligheten att exekvera kod i bakgrunden fått tagit ett steg bakåt. Även om det finns ett visst stöd för detta så är det betydligt mer komplicerat och man kommer ofta få gå över till att skriva kod i Swift respektive Kotlin för att lösa vissa mer plattformsspecifika delar.
När man ska bestämma sig för att använda Flutter eller ej så är detta en bra utgångspunkt. Ska appen köras i bakgrunden, eller direkt använda mer avancerad hårdvara så är det inte rekommenderat att använda Flutter. Appar som musikspelare, rena kamera-appar, träningsappar, appar som använder Bluetooth, o.s.v. är alltså mindre lämpliga kandidater.
Om fokus däremot ligger på själva användargränssnittet och aktiv användning så kan Flutter mycket väl vara ett bra alternativ.
Sammanfattning
Flutter ger dig en avancerad, modern, och högpresterande lösning för att bygga appar. I dagsläget så har fokus legat på iOS och Android, men ramverket har också beta-stöd för webb och desktop (macOS, Windows och Linux). Google satsar stenhårt på att utveckla ramverket och andelen utvecklare som använder Flutter växer dagligen. I dagsläget är Flutter mer populärt än React Native på både GitHub och StackOverflow.
Sammantaget så ser framtiden för Flutter väldigt ljus ut. Tack vare att det har ett stort företag bakom sig, som dessutom driver utvecklingen av den vanligaste mobilplattformen idag (Android), så lämpar sig Flutter mycket väl för många olika typer av applikationer.
Du kan läsa mer om Flutter och hur man bygger appar på https://flutter.dev
För att läsa mer av Erik Hellman kan du klicka in på hans egen blog https://hellsoft.se

Erik Hellman
Mobilutveckling, IoT, Backend/Cloud & Webb